../
Email about bridging RTL
- thangellamudiBridgingRTLAssertion2026’s dataset is not the same as liuRTLCoderFullyOpenSource2025
- Furthermore, thangellamudiBridgingRTLAssertion2026 doesn’t contain verbatim source code of luRTLLMOpenSourceBenchmark2023 . Though, it does contain example with similar module names.
- liuRTLCoderFullyOpenSource2025 already demonstrated that using their dataset helps small models to rival the performance of frontier models on luRTLLMOpenSourceBenchmark2023 benchmark
- But, they include a crucial step. They use Rouge-L metric to compute similarity between the dataset and the benchmark. They remove all the examples that exceed a certain threshold. In their case it resulted in the removal of 100 examples. Then the train their models.
My conclusions
- I think thangellamudiBridgingRTLAssertion2026 use the technique suggested in liuRTLCoderFullyOpenSource2025 to generate their own dataset. I perused through some examples and it seem AI-generated.
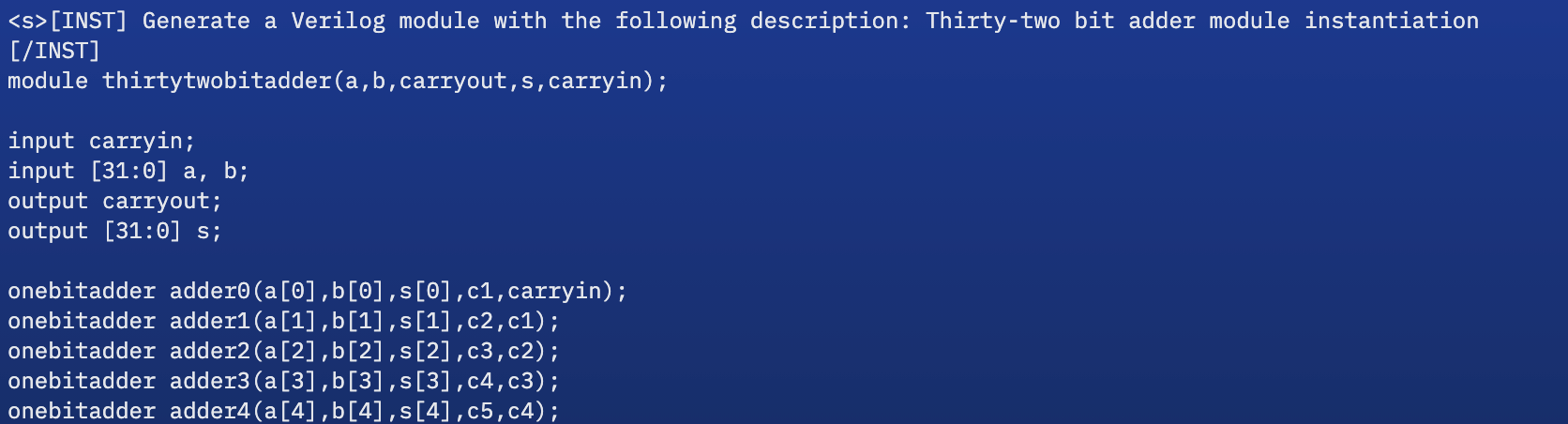 I am fairly certain no human would ever name their modules like this.
I am fairly certain no human would ever name their modules like this. - The SVADataset sometimes doesn’t have any assertions
- Sometime the assertions are of the flavor
assert (WIDTH>0) else fatal()which is akin to Cassertthan what we are looking for. - I do think the performance is real. liuRTLCoderFullyOpenSource2025 using Mistral and Deepseek do get good results. But Idk why the authors used Llama2 in 2026.
- This may indicate that the benchmark is too weak.
- I will make another pass to be sure about the details.