../
Deep Dive into LLMs like ChatGPT
How are these models trained?
Pretraining
Get data
First step in training a model is to get huge amounts of high quality text. An example would be https://huggingface.co/datasets/HuggingFaceFW/fineweb. Each company may have their own flavor of this. But the crux is:
- They scour the internet and gather all good webpages, documents, books, articles as possible
- They do some pre-processing that they end up with just text
Tokenization
- Neural network expect their data to be in a numerical format. You may think “Why cannot we just use the binary representation?”. In theory we could have a vocabulary of just ${0, 1}$ but the terms and the sequences are going to be extremely long. Due to computational restrictions we have a tradeoff between vocabulary size and sequence lengths.
- An example would be only considering bytes. Each byte is 8 bits longs. So our vocabulary size is 256. We convert all of our text using this encoding.
- In practice we use techniques such as Byte Pair Encoding to do this. A vocabulary size of around 100k seems to work well.
- You can check how GPT does this on https://tiktokenizer.vercel.app/
Neural Network Training
- We want to model the statistical relationship of how these tokens follow each other in the training corpus
- To summarize the training process
- We set some
MAX_WIDTH, this will be our context window. What we are trying to train is the prediction of the next token given this context window. - We randomly sample a context from the dataset and ask the model what comes next. The output of the model is probabilities for all the tokens in its vocabulary. We then pick the token that has the highest probability as the final output.
- We set some
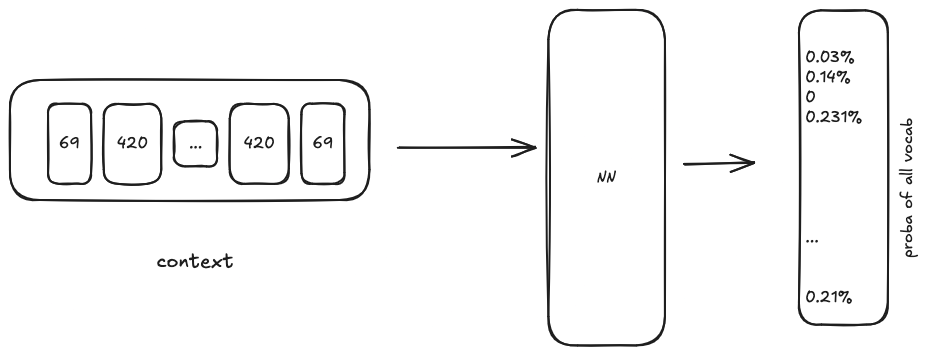
Visit https://bbycroft.net/llm for the actual architecture of a large language model.
Inference
- We feed the prompt to the model ask it to predict the next token. We append the generated token to the context and ask the model to predict again. I am assuming that we do this until we reach a EOF token.