../
Final Documentation
19CSE357 Evaluation 3 - Pig and Hive
By Deebakkarthi C R [CB.EN.U4CSE20613]
Dataset
- The dataset used is Yelp Dataset
- The tables in this dataset is
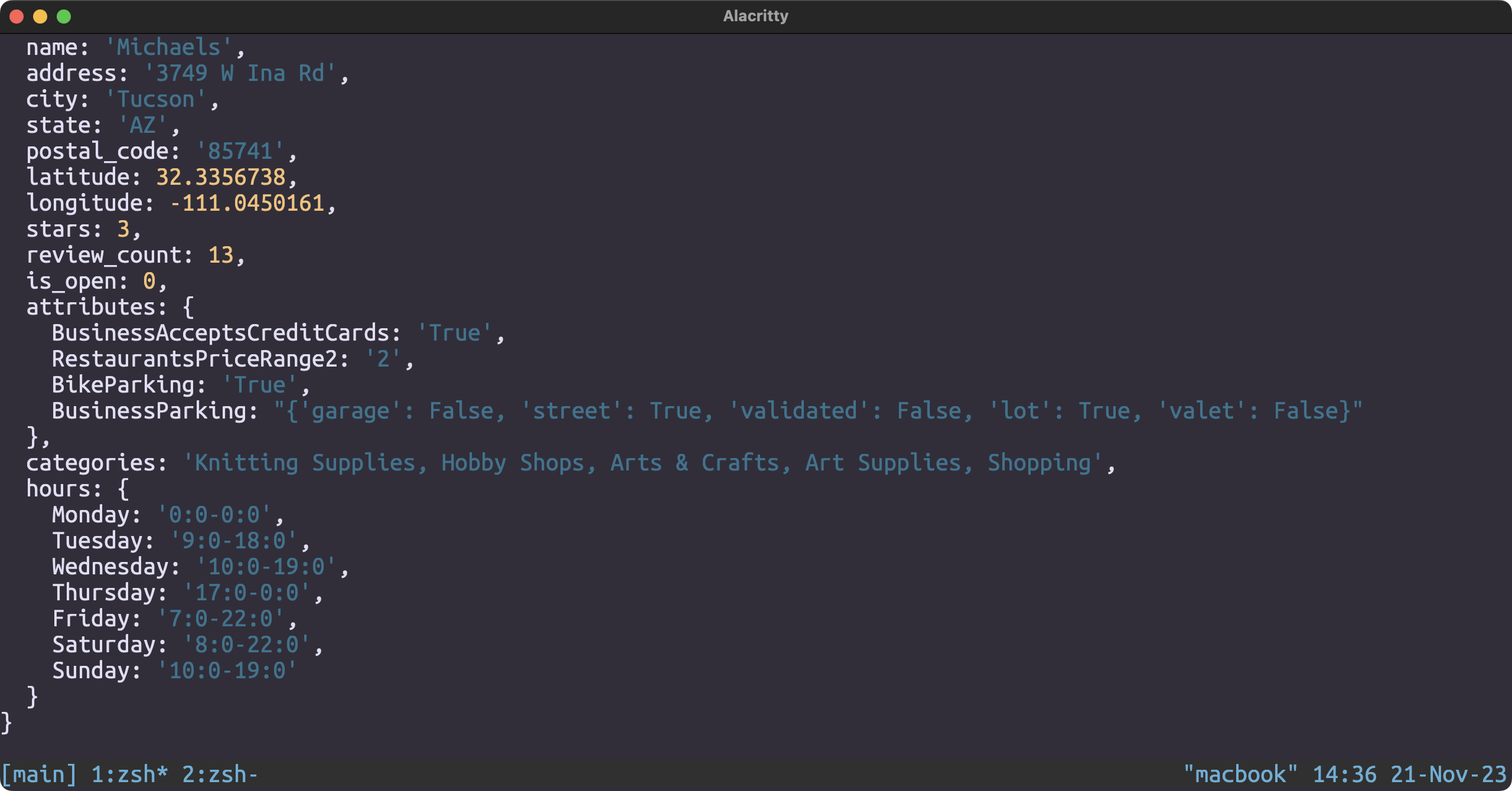
- Business
- business_id
- name
- address
- city
- state
- postal code
- latitude
- longitude
- stars
- review_count
- is_open
- attributes
- categories
- hours
- Review
- review_id
- user_id
- business_id
- stars
- date
- text
- useful
- funny
- cool
- Users
- user_id
- name
- review_count
- yelping_since
- friends
- useful
- funny
- cool
- fans
- elite
- average_stars
- compliment_hot
- compliment_more
- compliment_profile
- compliment_cute
- compliment_list
- compliment_note
- compliment_plain
- compliment_cool
- compliment_funny
- compliment_writer
- compliment_photos
- Checkin
- business_id
- date
- Tips
- text
- date
- compliment_count
- business_id
- user_id
- Photos
- photo_id
- business_id
- caption
- label
- Business
| Table | No. of Records |
|---|---|
| Business | $150,000$ |
| Review | $6,900,000$ |
Salient features of this dataset
- Rich and diverse data
- Real-world data
- Large Scale
- Social Network aspects
Pig
Basic Queries
Loading Data
tips_json_parsing = LOAD '/user/hduser/yelp/tip.json' USING JsonLoader('user_id:chararray, business_id:chararray, text: chararray, data: chararray, compliment_count:int');
Number of comments by each user
group_user = GROUP tips_json_parsing BY user_id;
tmp = FOREACH group_user GENERATE group, COUNT(tips_json_parsing);
dump tmp;
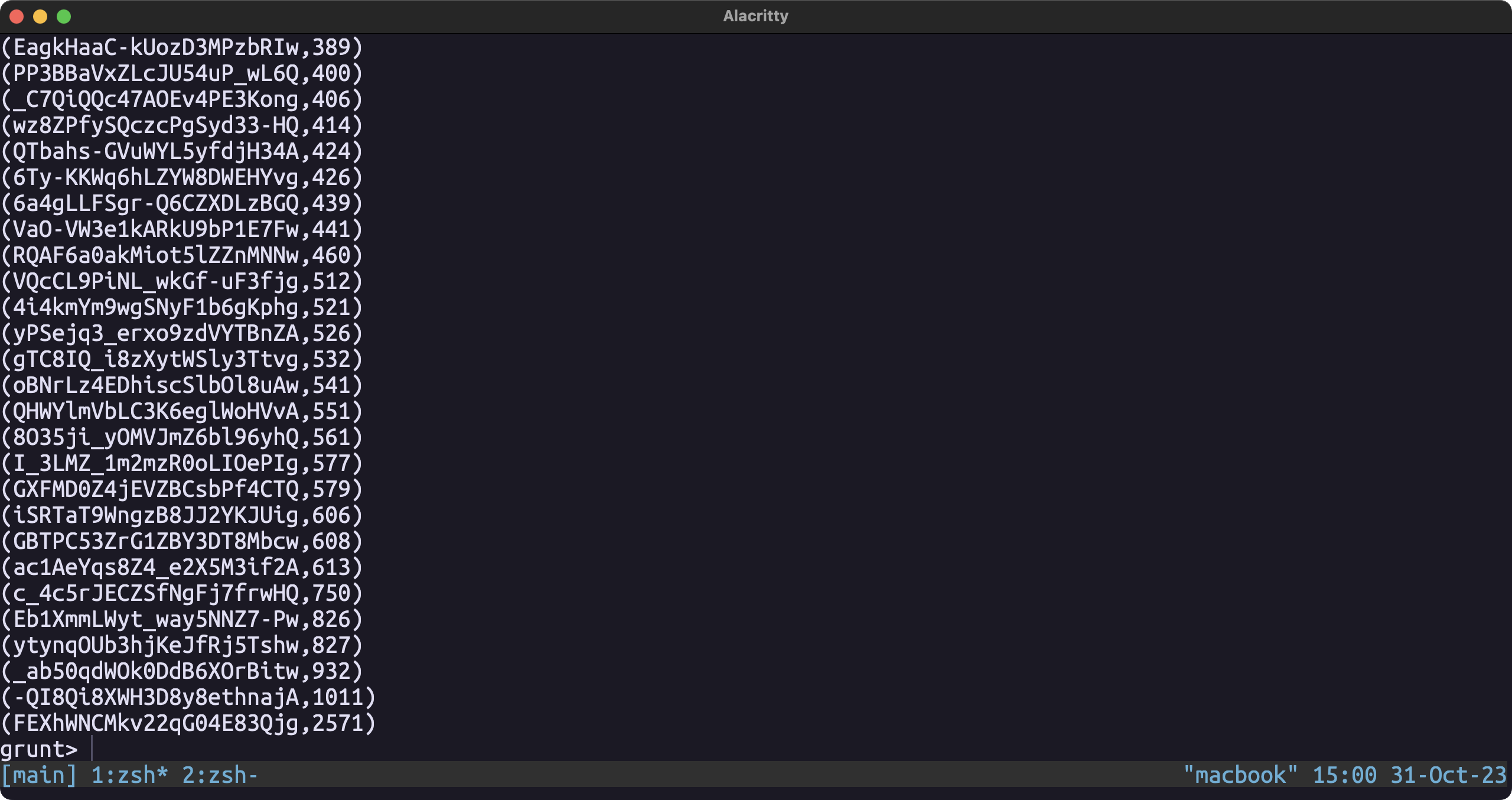
User with the most comments
tmp2 = ORDER tmp by $1
User with most compliments
group_user = GROUP tips_json_parsing BY user_id;
tmp = FOREACH group_user GENERATE (tips_json_parsing.compliment_count, SUM(tips_json_parsing.compliment_count));
tmp2 = ORDER tmp BY $0;
dump tmp2;
Restaurant with the most compliments
group_user = GROUP tips_json_parsing BY business_id;
tmp = GROUP tips_json_parsing BY business_id;
tmp2 = FOREACH tmp GENERATE group, COUNT(tips_json_parsing.compliment_count);
tmp2 = ORDER tmp2 by $1;
dump tmp2
Complex Queries
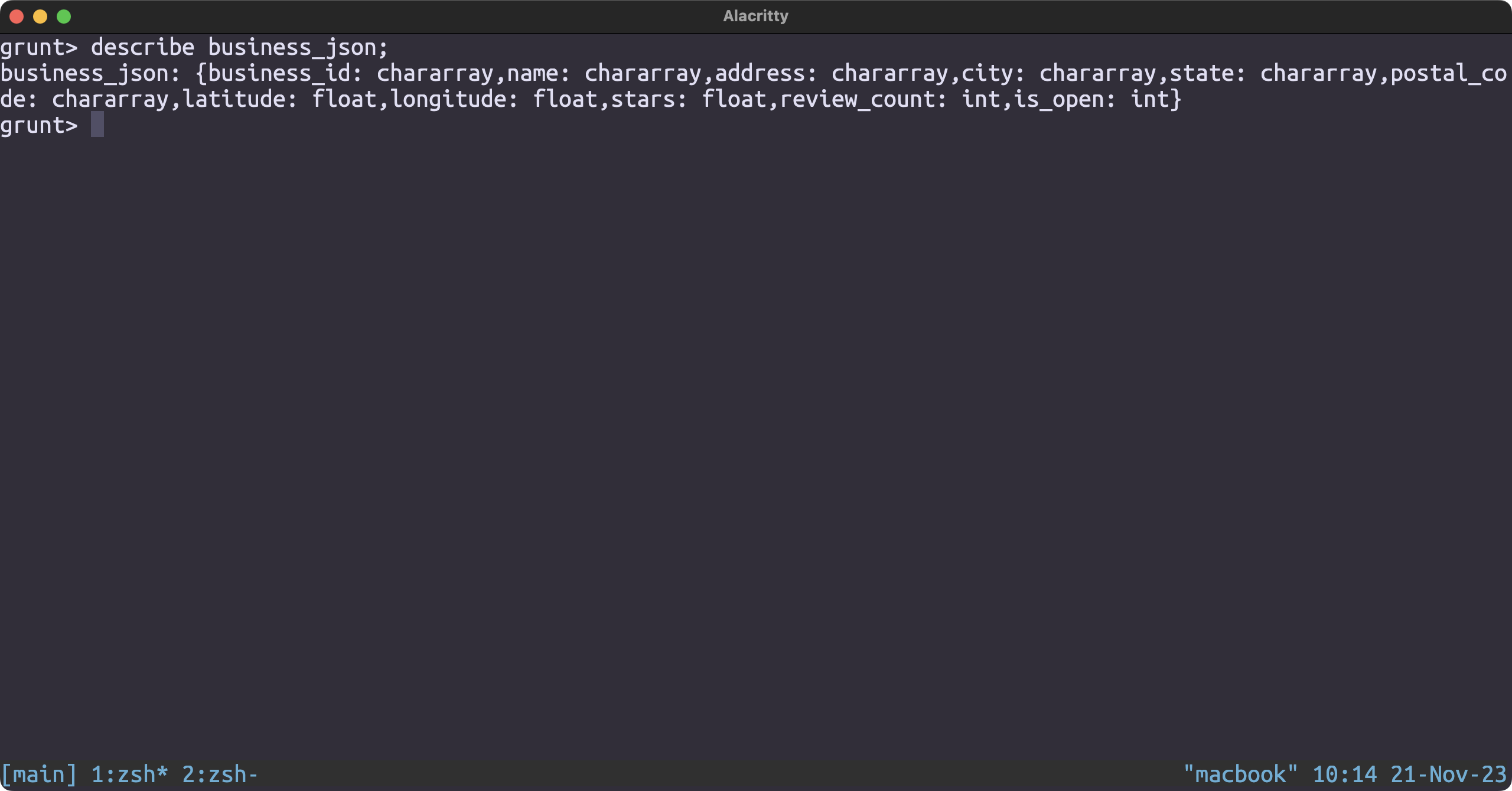
Loading the dataset
business_json = LOAD '/user/hduser/yelp/business.json' USING JsonLoader('business_id:chararray, name:chararray, address:chararray, city:chararray, state:chararray, postal_code:chararray, latitude:float, longitude:float, stars:float, review_count:int, is_open:int');
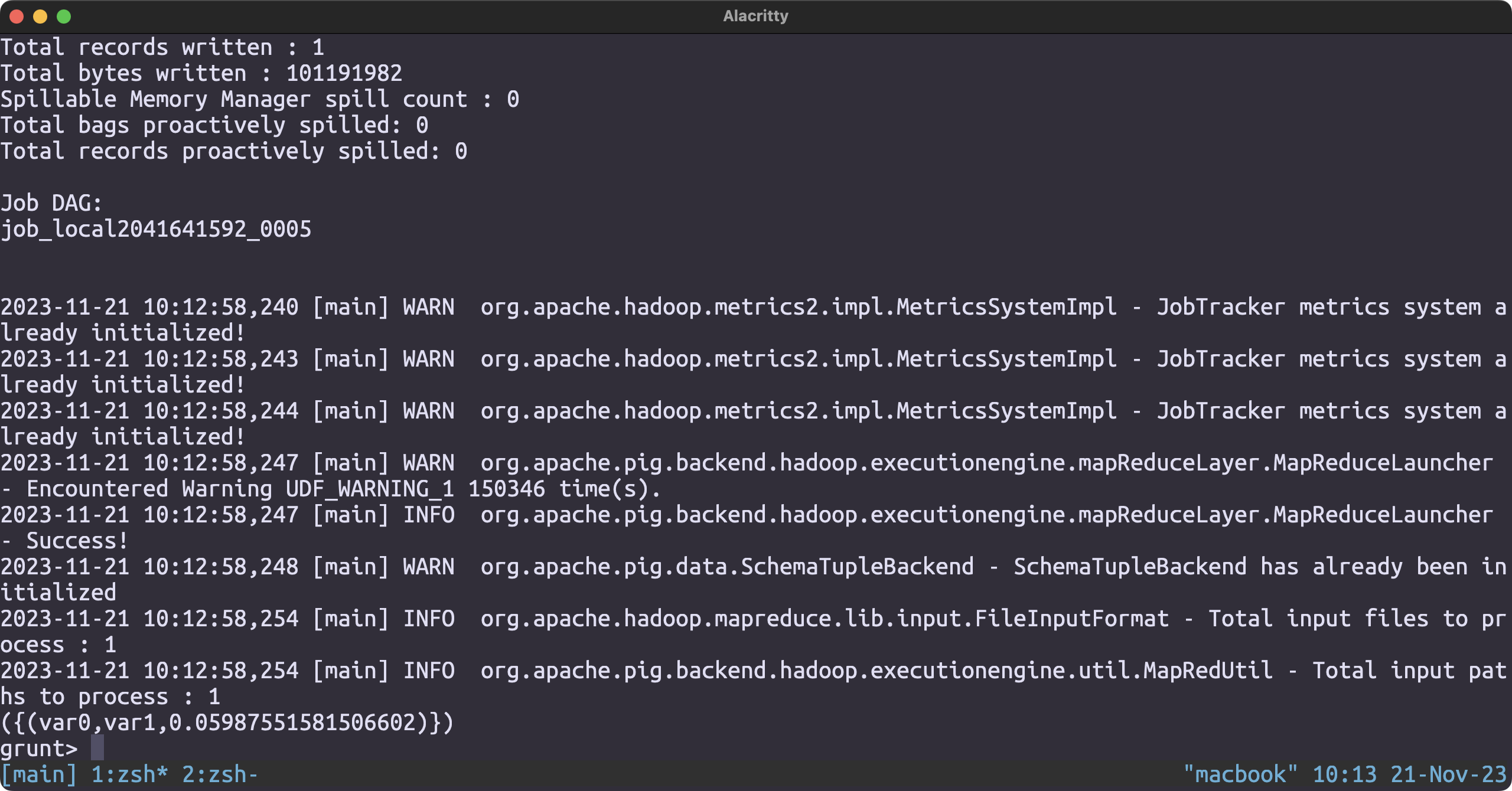
Correlation Coefficient of review_count and stars
review_and_stars = FOREACH business_json GENERATE (double)stars, (double)review_count;
rel = GROUP review_and_stars BY ALL;
corop = FOREACH rel GENERATE COR(review_and_stars.stars, review_and_stars.review_count);
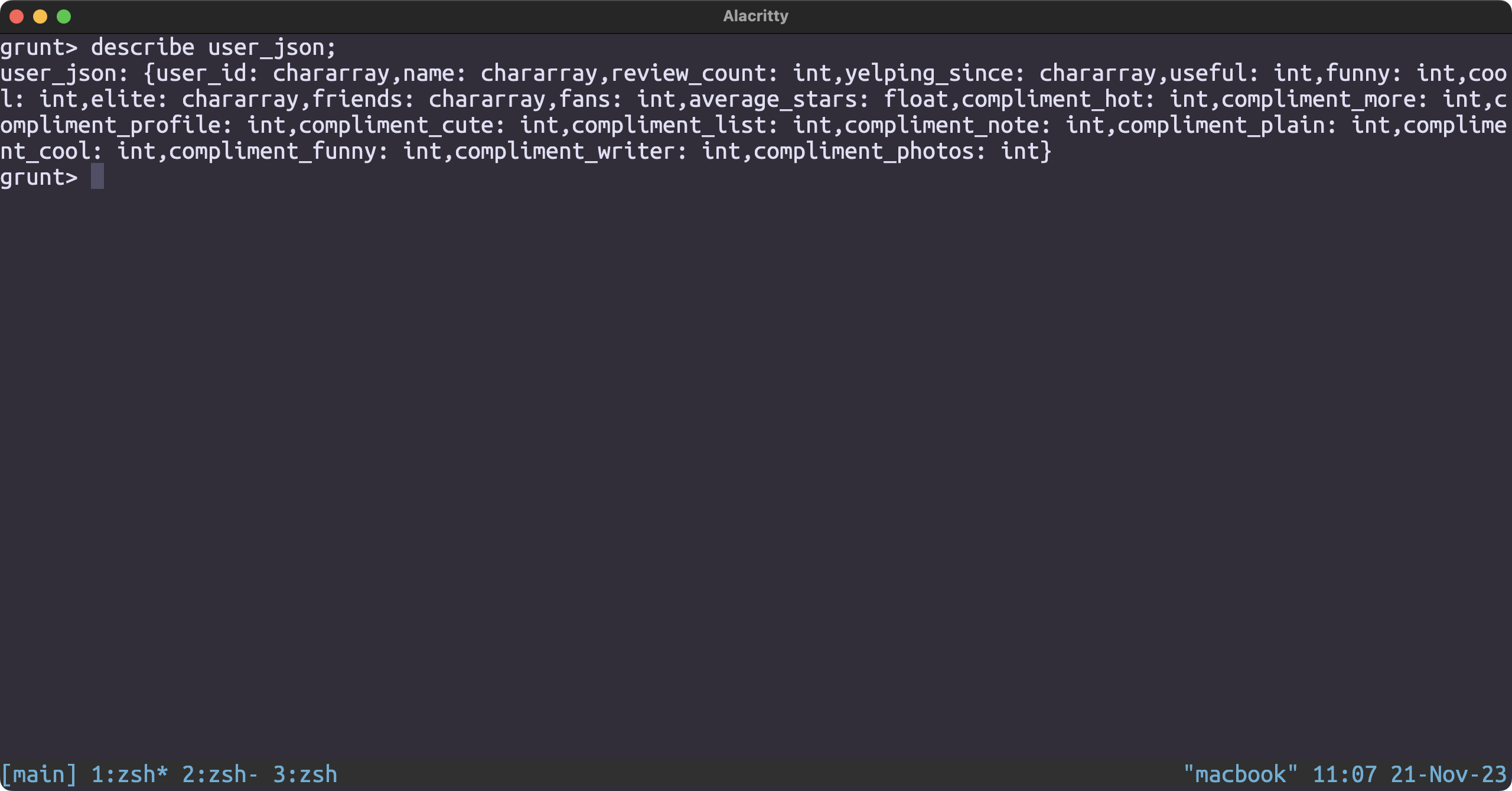
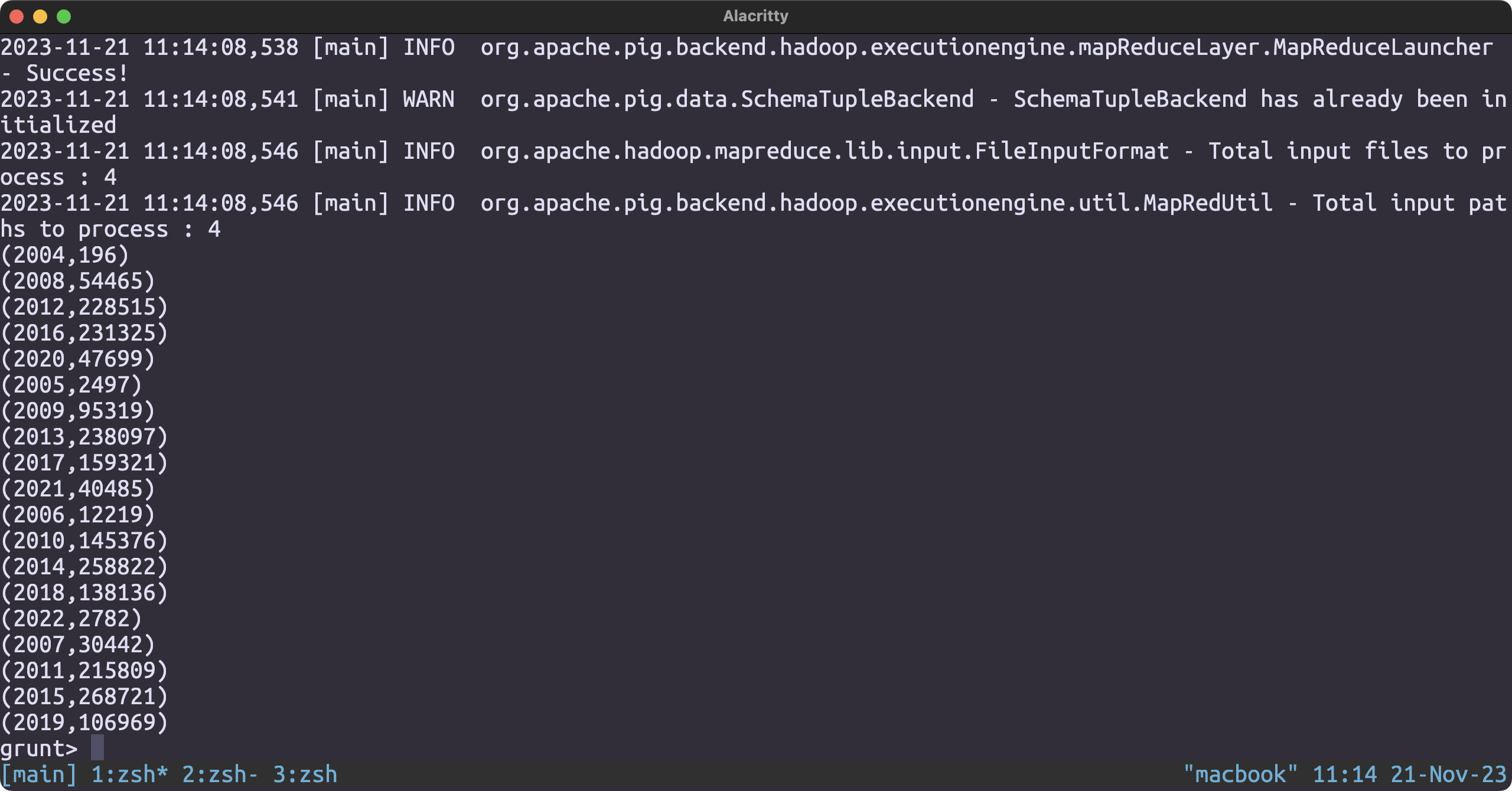
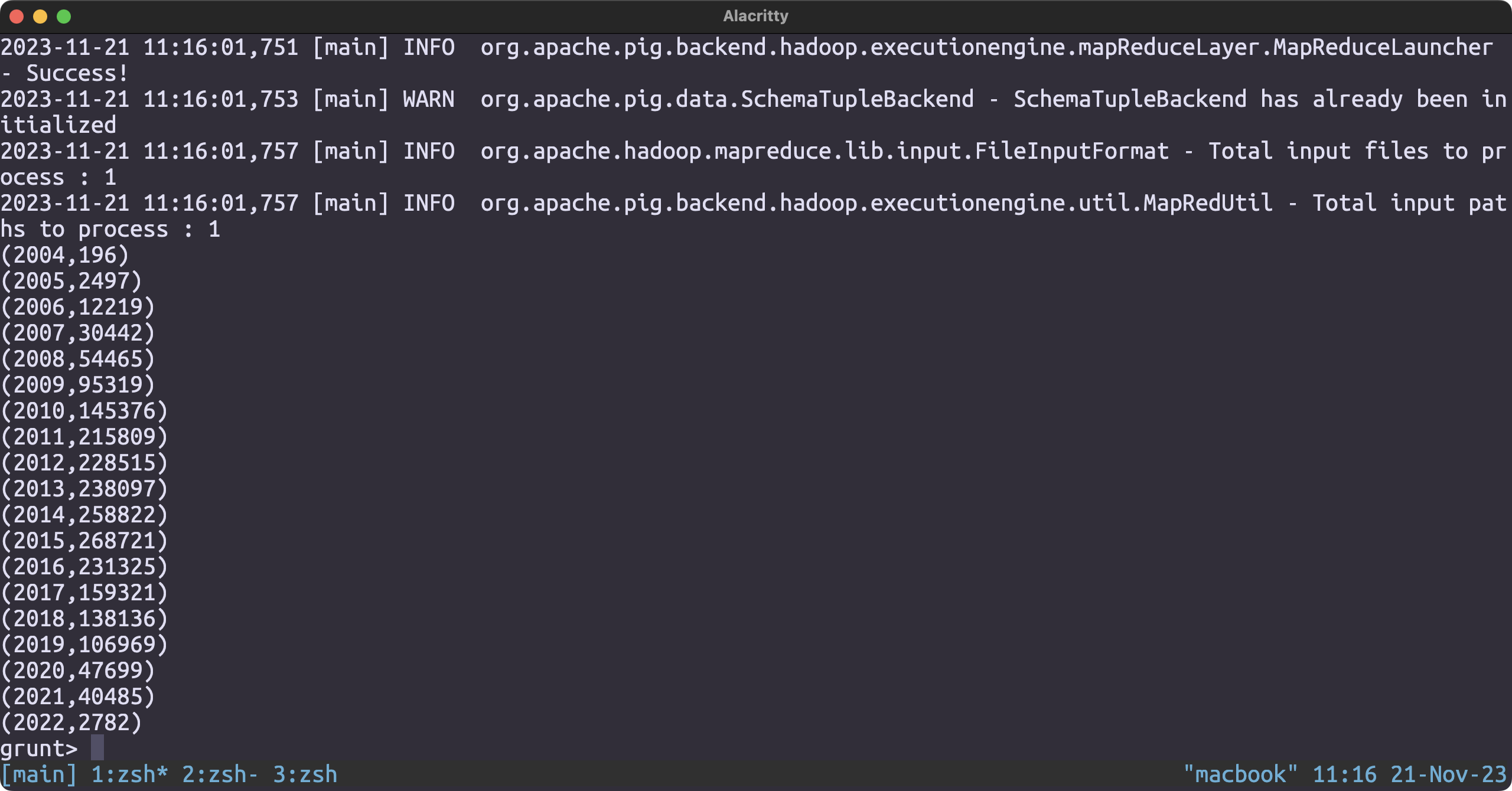
Which year produced the most number of elite users
Loading the dataset
user_json = LOAD '/user/hduser/yelp/user.json' USING JsonLoader('user_id:chararray, name:chararray, review_count:int, yelping_since:chararray, useful:int, funny:int, cool:int, elite:chararray, friends:chararray, fans:int, average_stars:float, compliment_hot:int, compliment_more:int, compliment_profile:int, compliment_cute:int, compliment_list:int, compliment_note:int, compliment_plain:int, compliment_cool:int, compliment_funny:int, compliment_writer:int, compliment_photos:int');
year_alone = FOREACH user_json GENERATE (int)SUBSTRING(yelping_since, 0, 4);
nr_elite_years = FOREACH user_json GENERATE SIZE(STRSPLIT(elite, ','));
year_and_nr_elite = FOREACH user_json GENERATE (int)SUBSTRING(yelping_since, 0, 4), SIZE(STRSPLIT(elite, ','));
grouped_data = GROUP year_and_nr_elite BY year;
result = foreach grouped_data GENERATE group, SUM(year_and_nr_elite.nr_elite);
sorted_result = ORDER result by $0;
Most popular user
user_and_nr_friends = FOREACH user_json GENERATE name, SIZE(STRSPLIT(friends, ','));
result = order user_and_nr_friends BY $1;
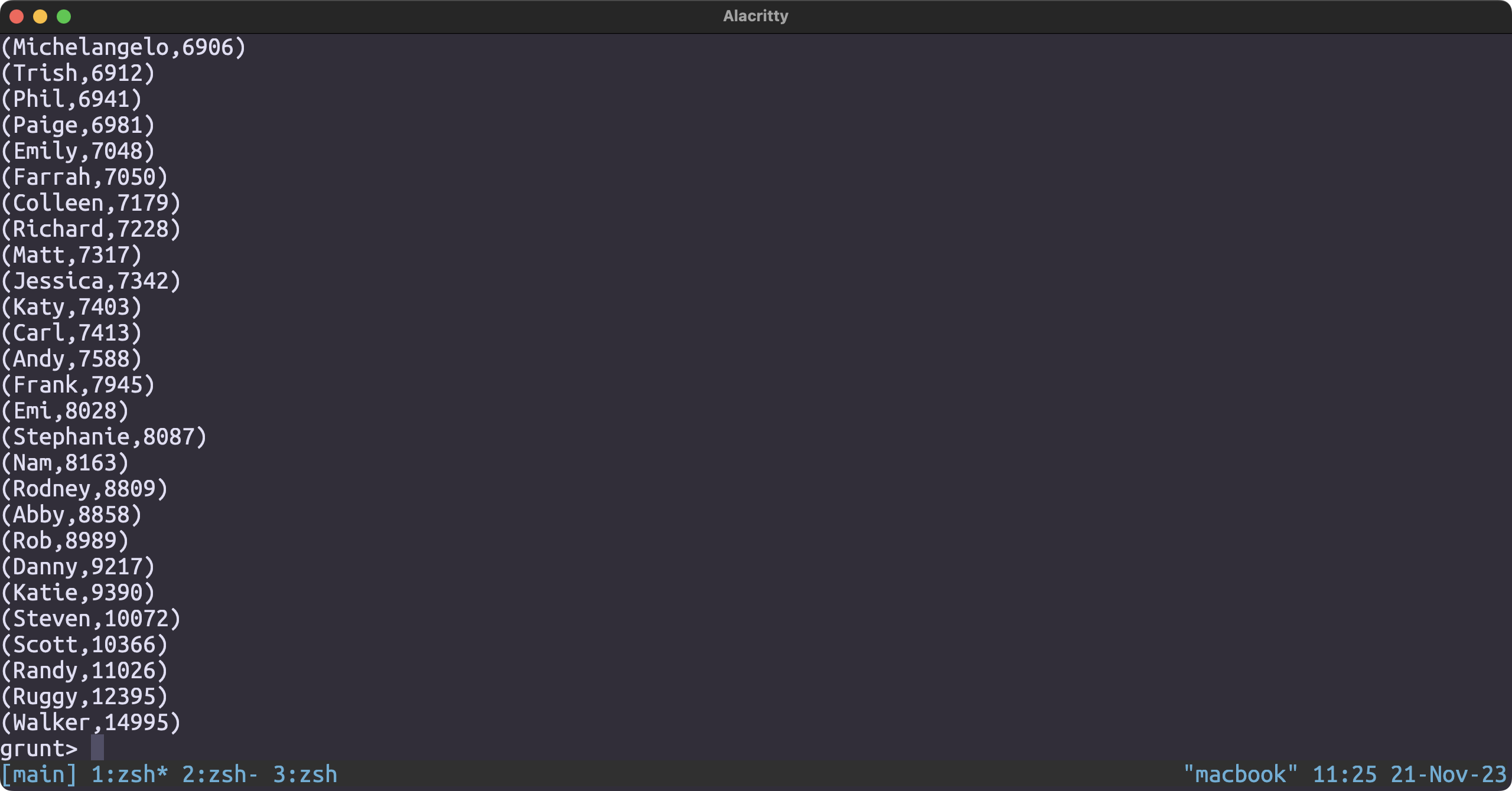
Most visited restaurant
Loading the dataset
checkin_json = LOAD '/user/hduser/yelp/checkin.json' USING JsonLoader('business_id:chararray, date:chararray');
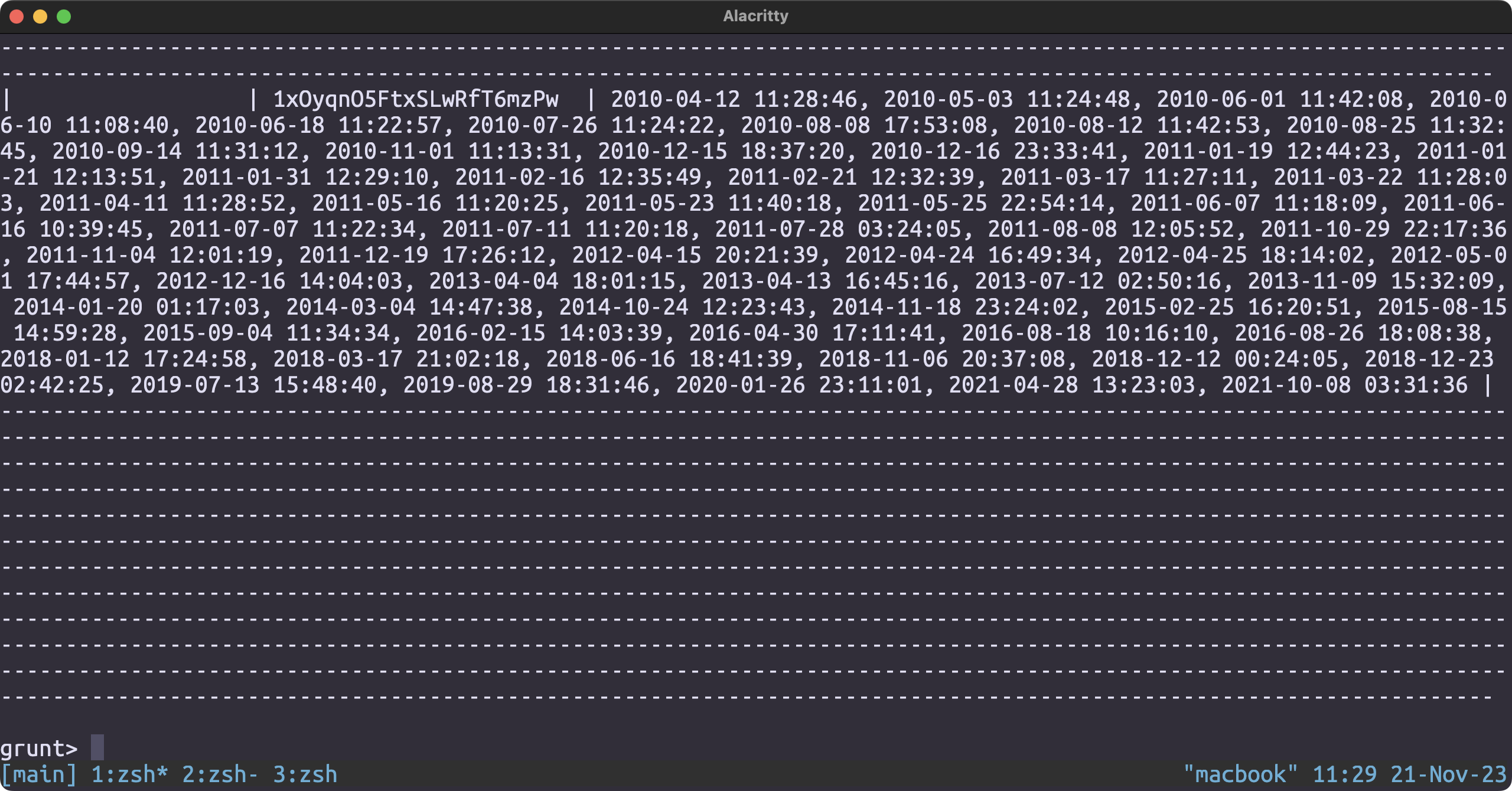
nr_visited = FOREACH checkin_json GENERATE business_id, SIZE(STRSPLIT(date, ','));
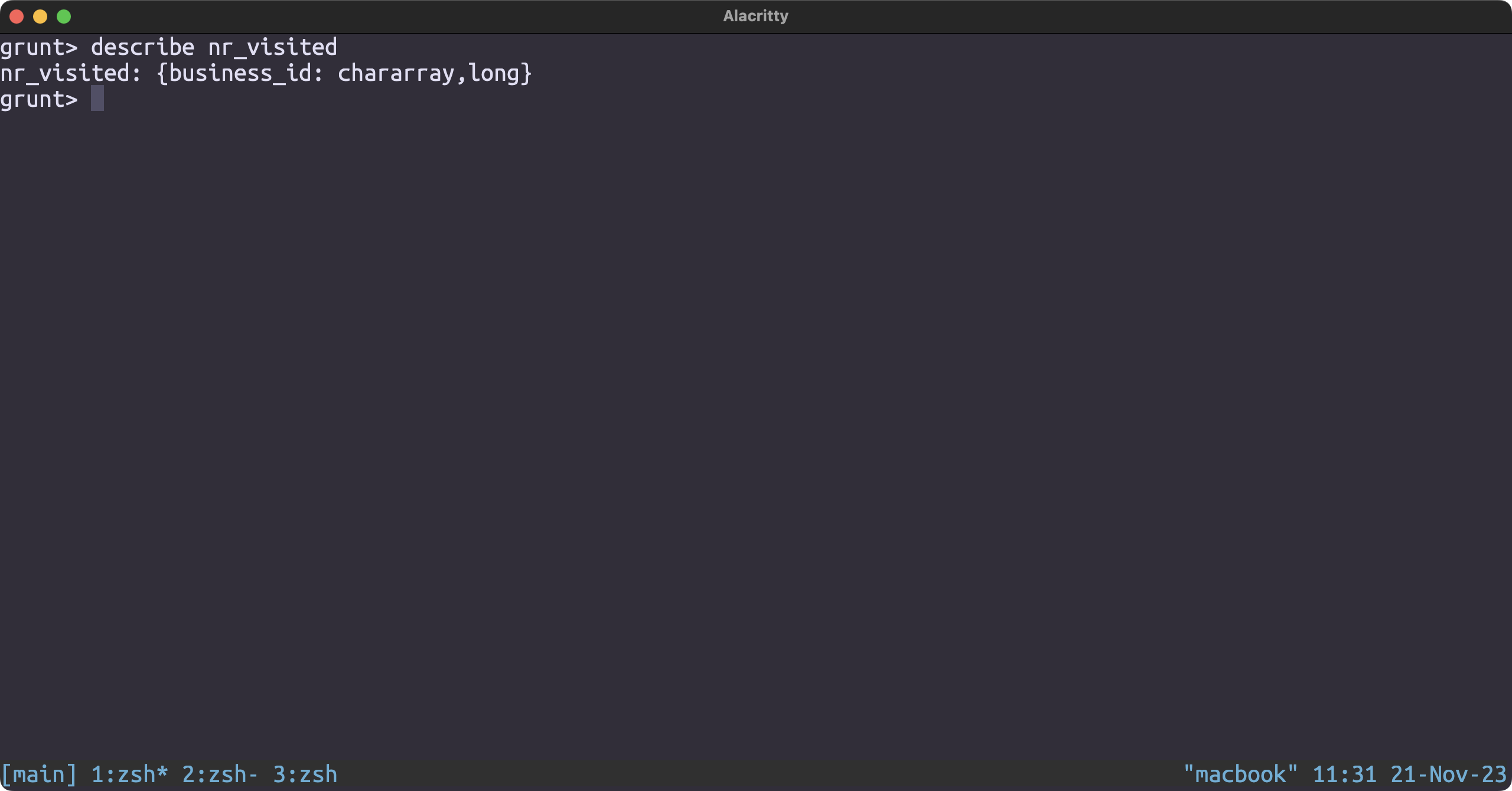
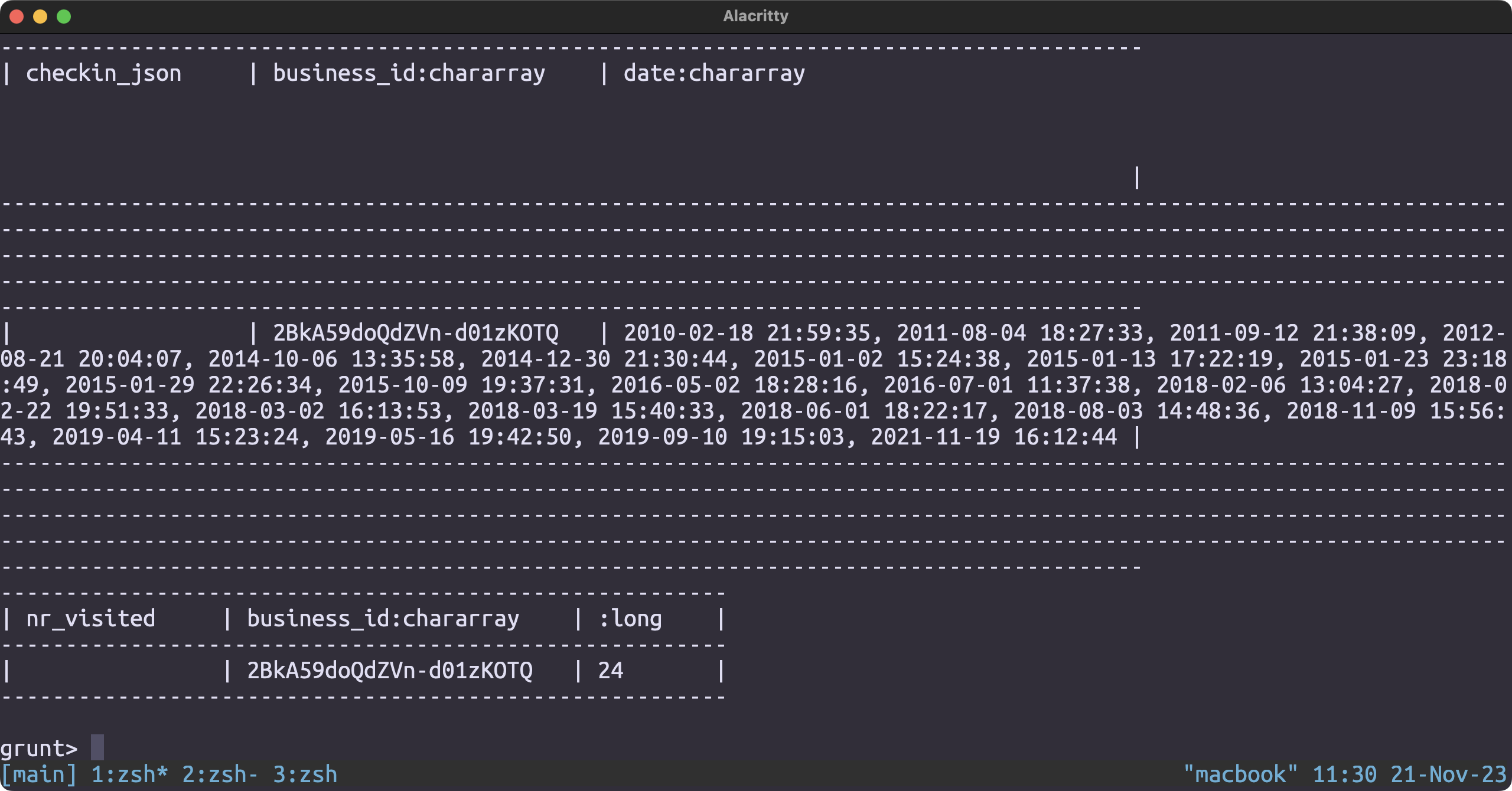
business_id_and_name = FOREACH business_json generate business_id, name;
result = join most_visited by business_id, business_id_and_name by business_id;
result = order result by $1;
UDF
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
public class GroupDatesByYear extends EvalFunc<String> {
public String convertMapToString(Map<String, Integer> map) {
StringBuilder mapAsString = new StringBuilder("{");
for (String key : map.keySet()) {
mapAsString.append(key + "=" + map.get(key).toString() + ", ");
}
mapAsString.delete(mapAsString.length() - 2, mapAsString.length()).append("}");
return mapAsString.toString();
}
public String exec(Tuple input) throws IOException {
if (input == null || input.size() == 0)
return null;
String str = (String) input.get(0);
String[] timestamps = str.split(",");
Map<String, Integer> hm = new HashMap<String, Integer>();
for (String timestamp : timestamps) {
String year = timestamp.strip().split(" ")[0].split("-")[0];
Integer tmp = hm.get(year);
if (tmp == null) {
hm.put(year, 1);
} else {
hm.put(year, tmp + 1);
}
}
return convertMapToString(hm);
}
}
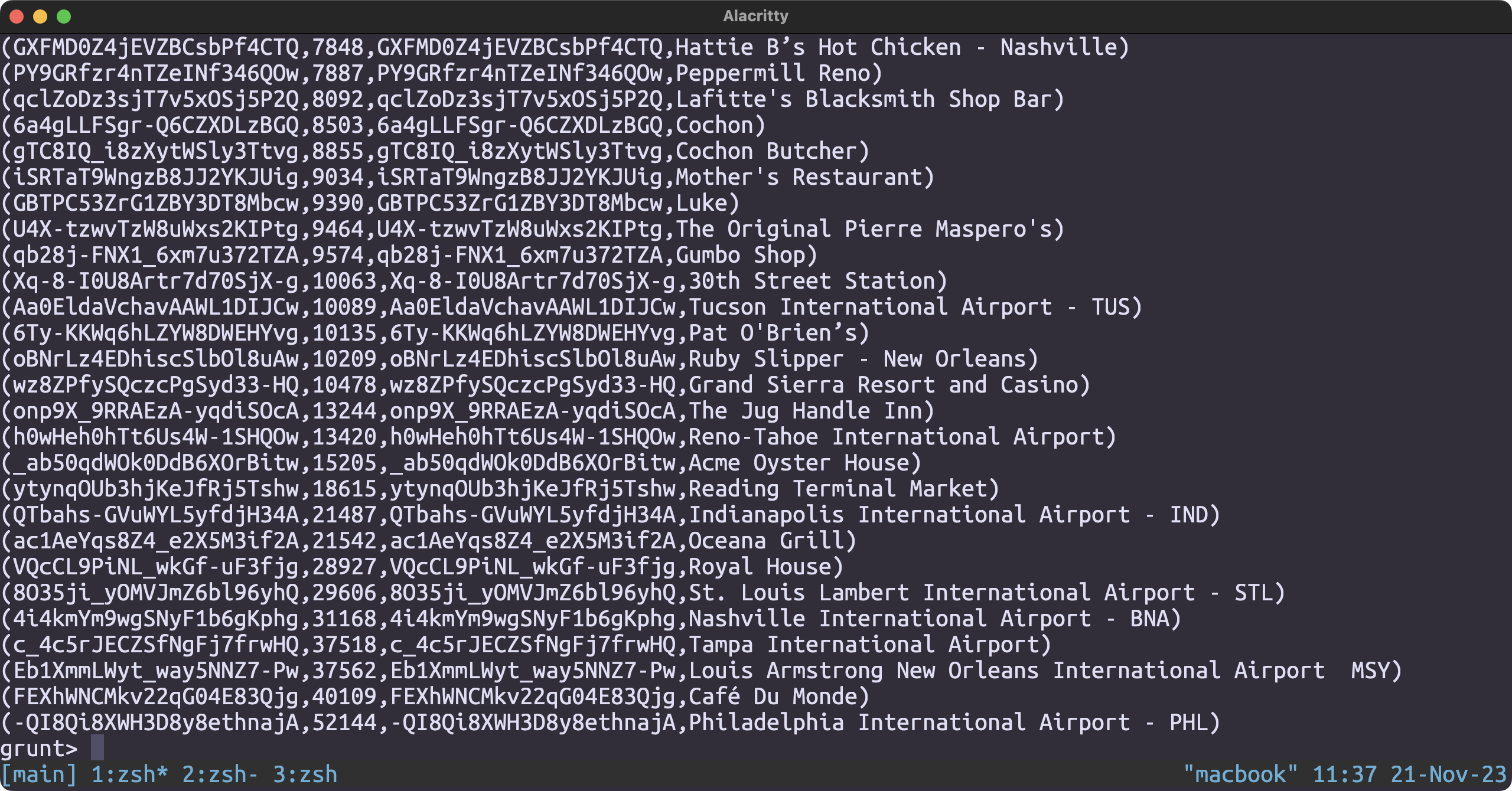
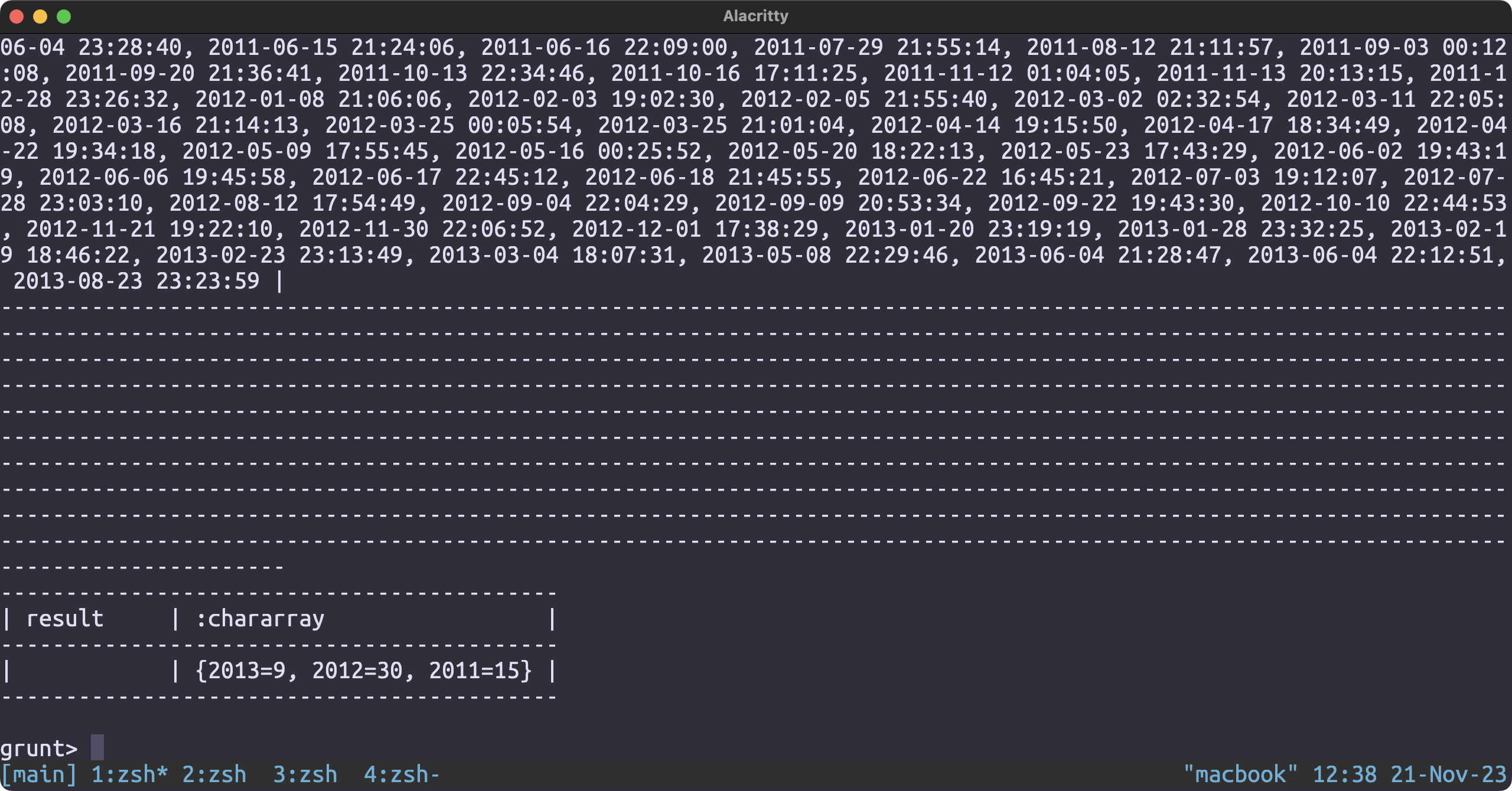
REGISTER './udf.jar';
checkin_json = LOAD '/user/hduser/yelp/checkin.json' USING JsonLoader('business_id:chararray, date:chararray');
result = FOREACH checkin_json GENERATE GroupDatesByYear(date);
illustrate;
MongoDB
Loading dataset
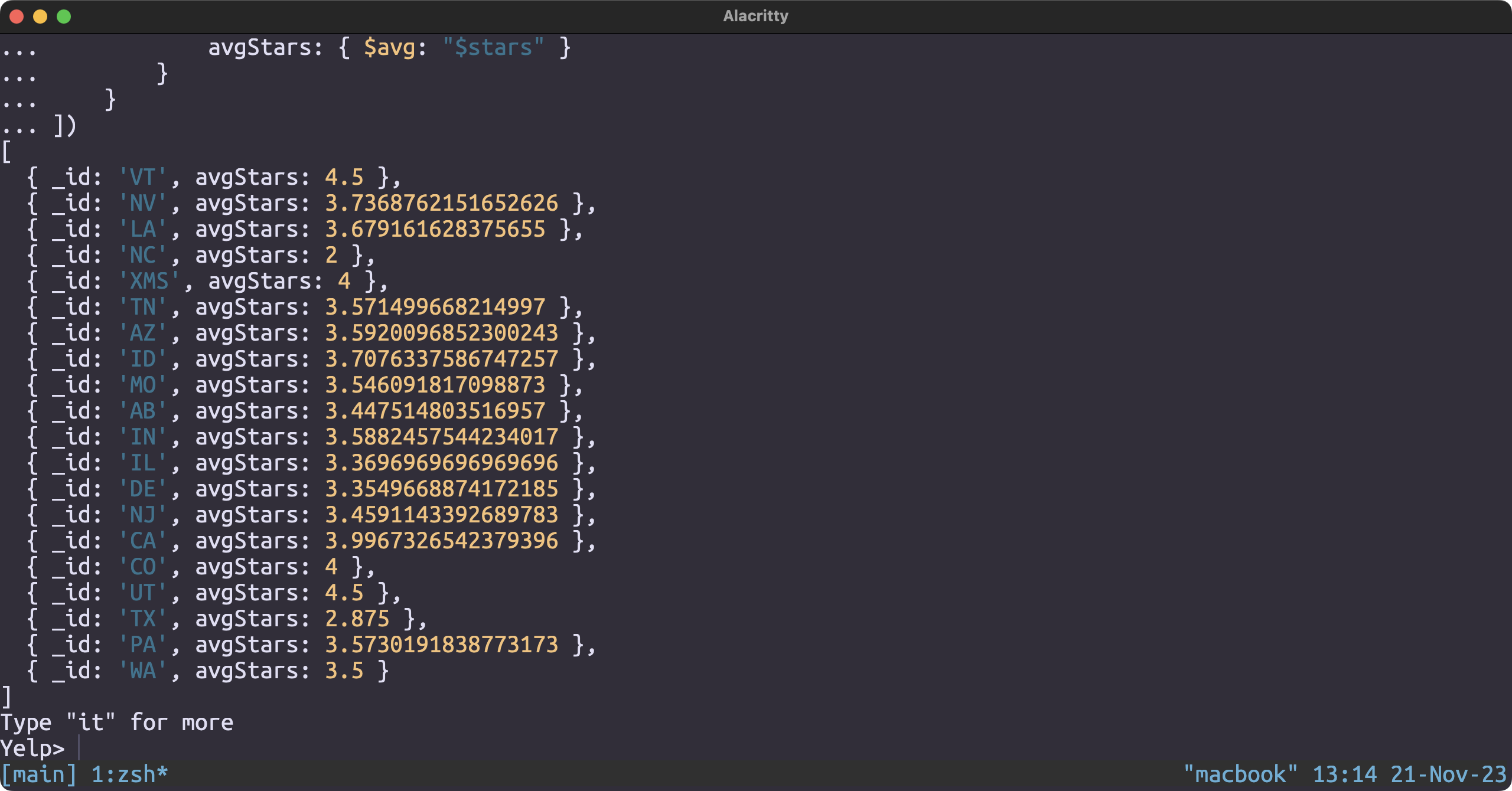
Average rating per state
db.business.aggregate([
{
$group: {
_id: "$state",
avgStars: { $avg: "$stars" }
}
}
])
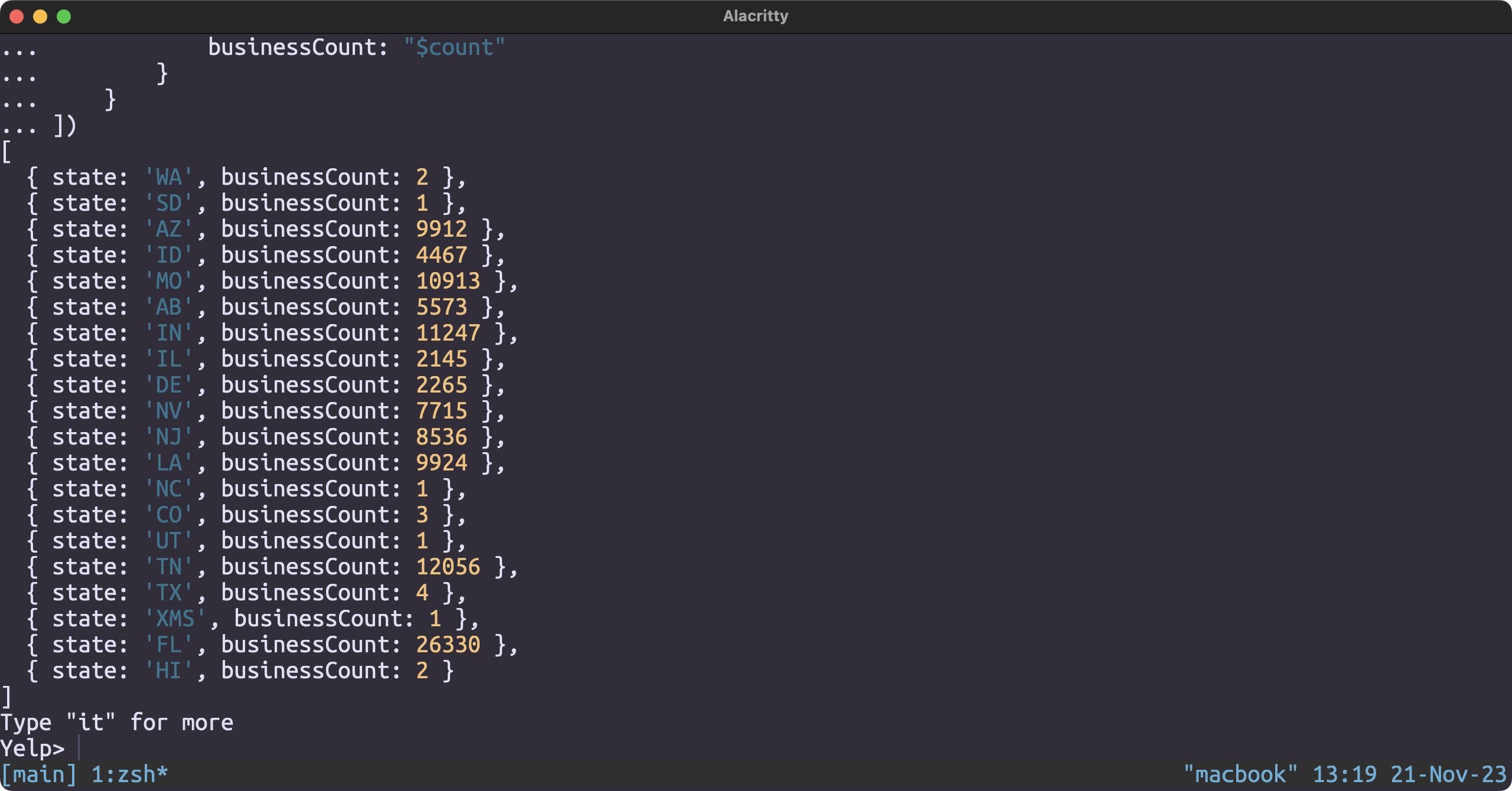
Number of restaurants per state
db.business.aggregate([
{
$group: {
_id: "$state",
count: { $sum: 1 }
}
},
{
$project: {
_id: 0,
state: "$_id",
businessCount: "$count"
}
}
])
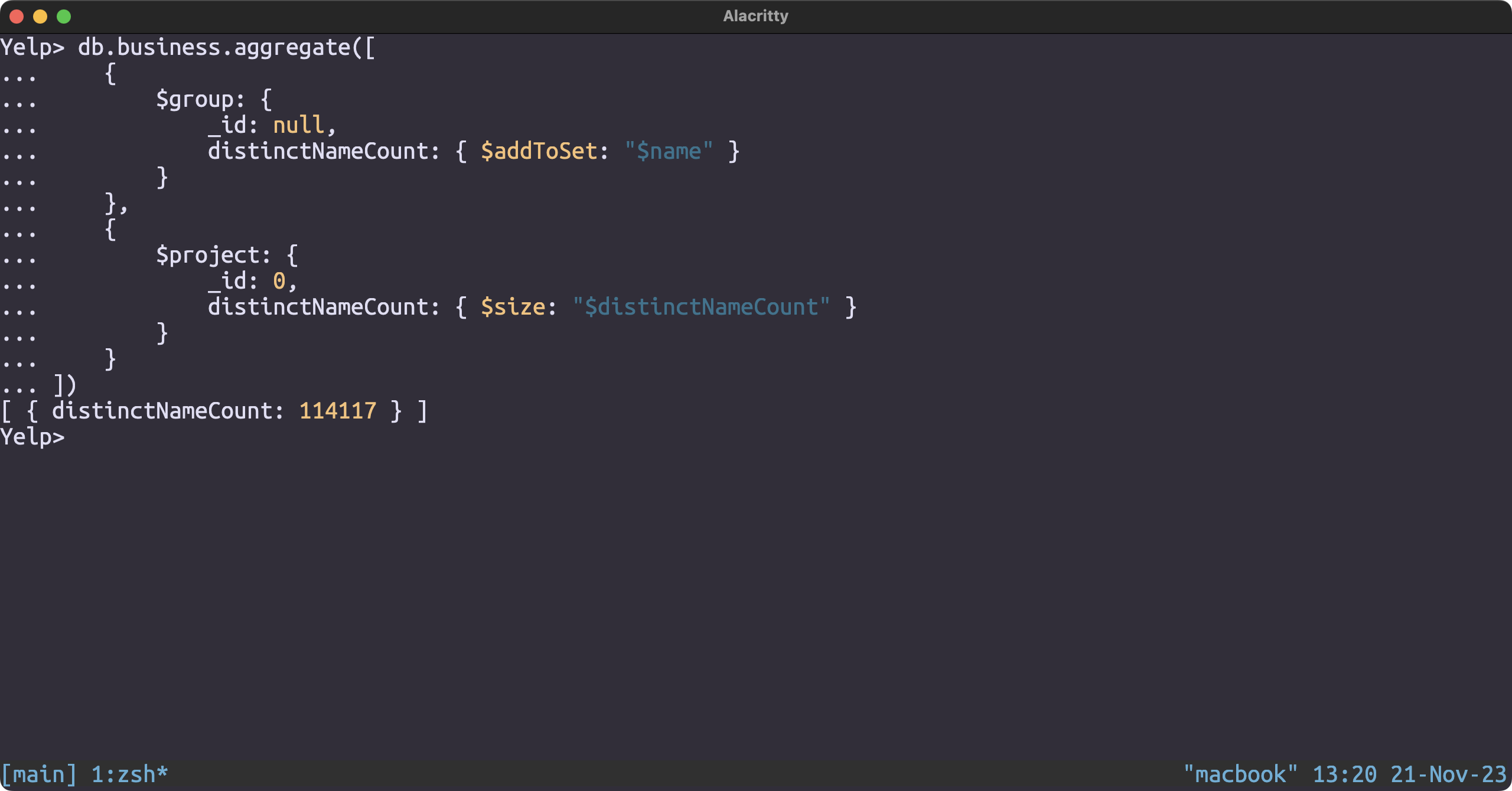
Number of distinct Restaurants
db.business.aggregate([
{
$group: {
_id: null,
distinctNameCount: { $addToSet: "$name" }
}
},
{
$project: {
_id: 0,
distinctNameCount: { $size: "$distinctNameCount" }
}
}
])
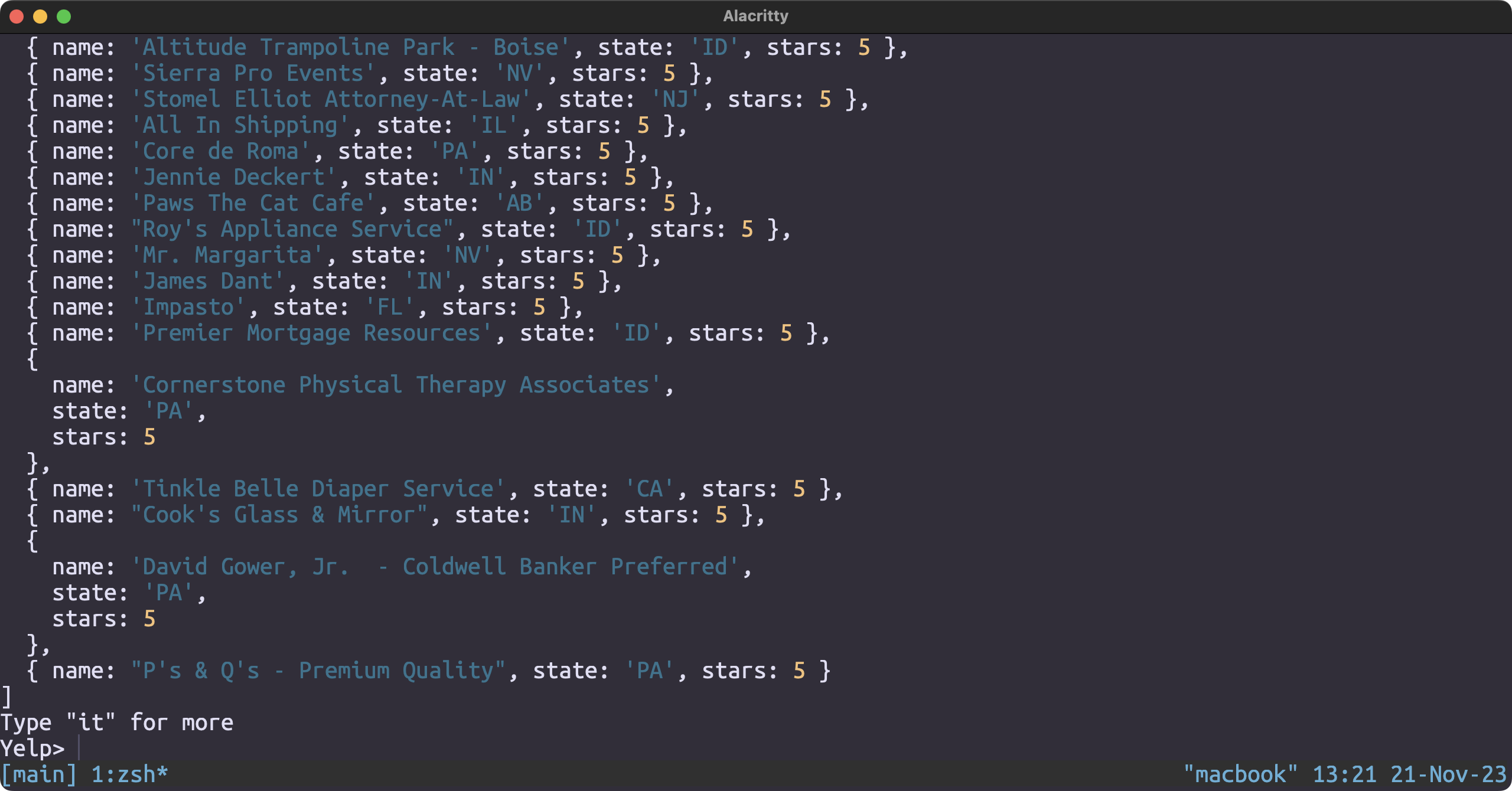
Top Rated Restaurant in each state
db.business.aggregate([
{
$lookup: {
from: "business",
let: { state: "$state", stars: "$stars" },
pipeline: [
{
$group: {
_id: "$state",
maxStars: { $max: "$stars" }
}
},
{
$match: {
$expr: {
$and: [
{ $eq: ["$$state", "$_id"] },
{ $eq: ["$$stars", "$maxStars"] }
]
}
}
}
],
as: "maxStarsData"
}
},
{
$unwind: "$maxStarsData"
},
{
$match: {
$expr: {
$and: [
{ $eq: ["$state", "$maxStarsData._id"] },
{ $eq: ["$stars", "$maxStarsData.maxStars"] }
]
}
}
},
{
$project: {
_id: 0,
state: 1,
stars: 1,
name: 1
}
}
])
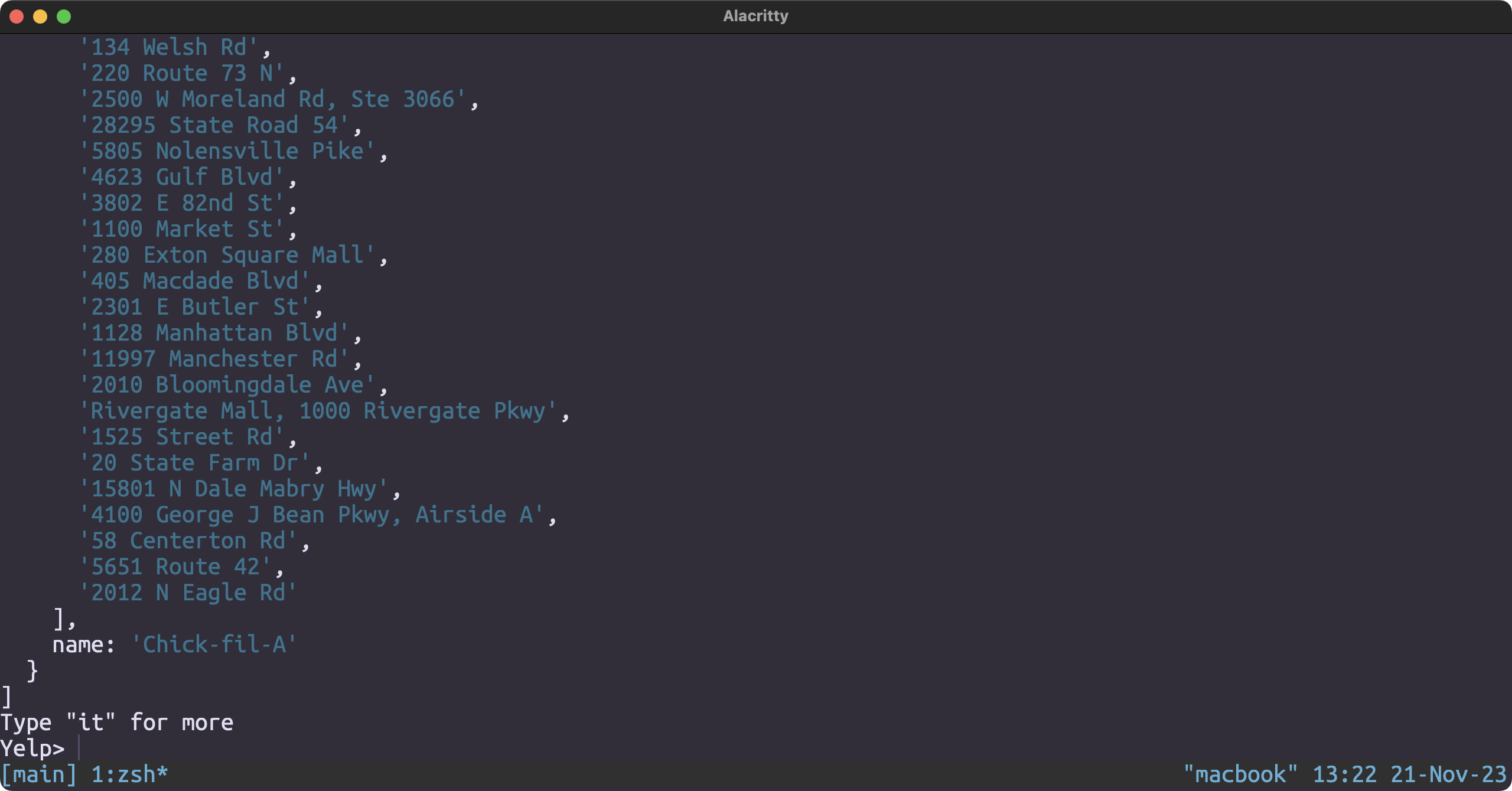
Restaurants with the most branches
db.business.aggregate([
{
$group: {
_id: "$name",
locations: { $addToSet: "$address" },
count: { $sum: 1 }
}
},
{
$match: {
count: { $gt: 1 }
}
},
{
$sort: {
count: -1
}
},
{
$project: {
_id: 0,
name: "$_id",
locations: 1
}
}
])
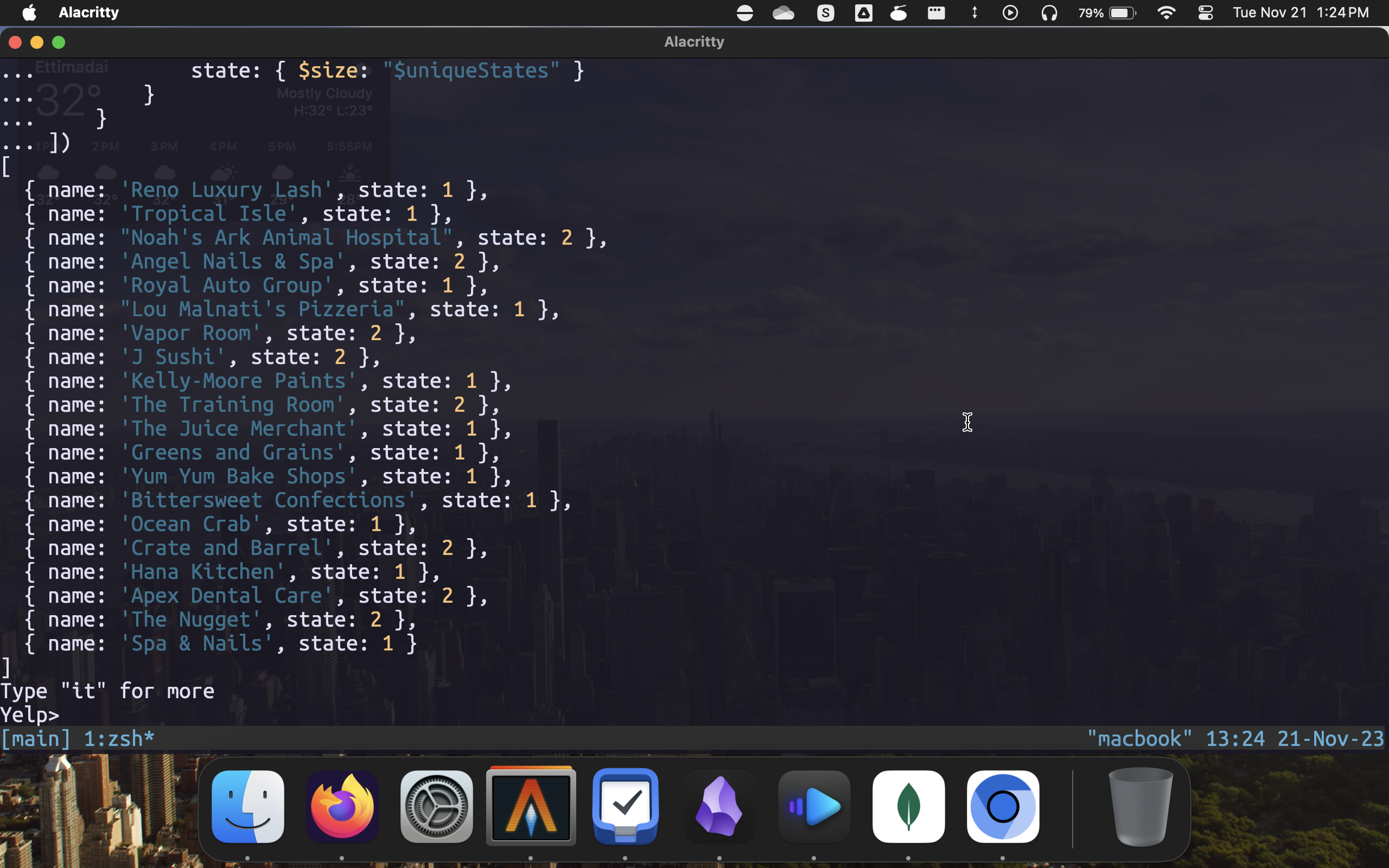
Restaurants which covers the most states
db.business.aggregate([
{
$group: {
_id: "$name",
uniqueStates: { $addToSet: "$state" },
count: { $sum: 1 }
}
},
{
$match: {
count: { $gt: 1 }
}
},
{
$sort: {
count: 1
}
},
{
$project: {
_id: 0,
name: "$_id",
state: { $size: "$uniqueStates" }
}
}
])
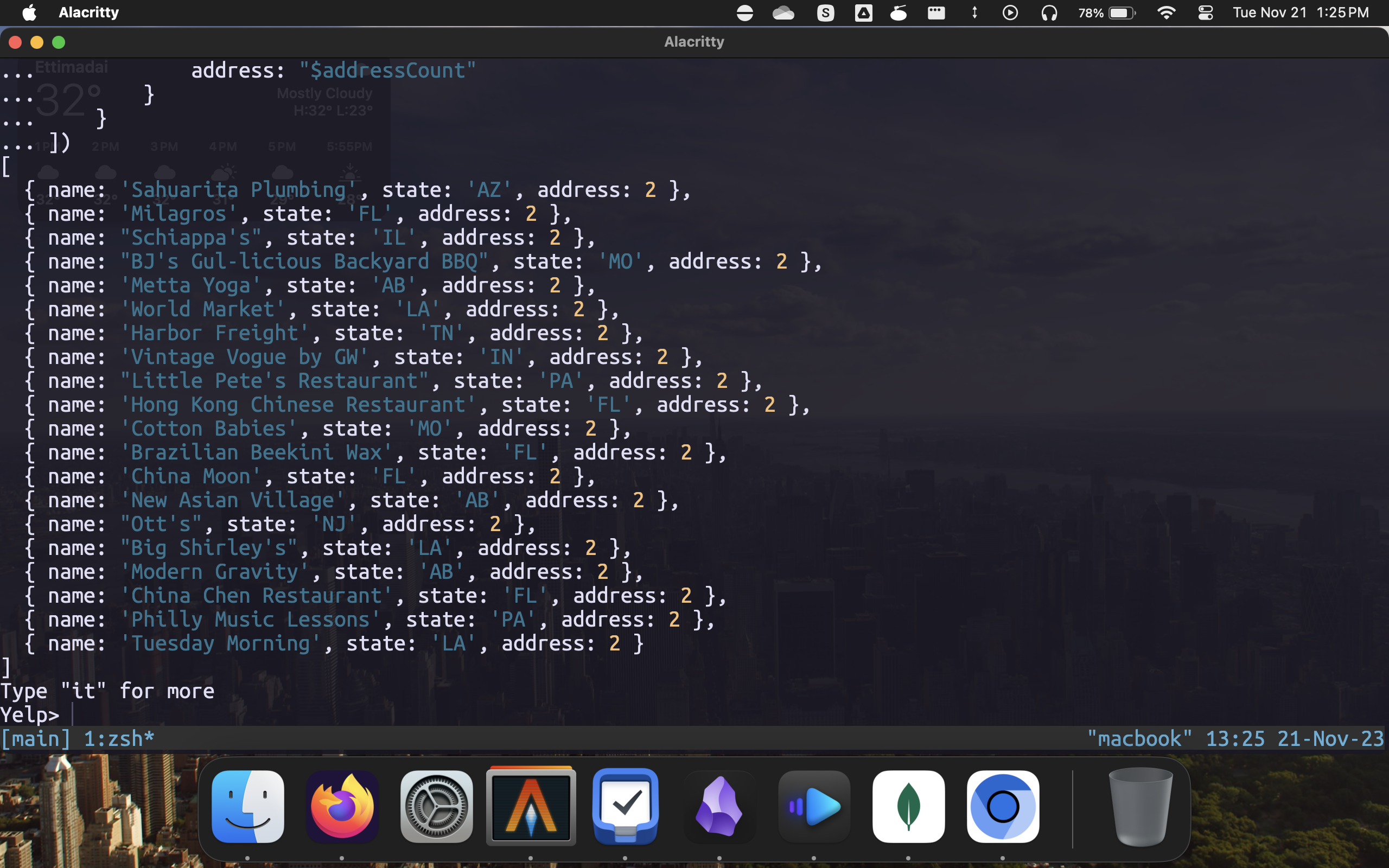
Number of branches per state
db.business.aggregate([
{
$group: {
_id: {
name: "$name",
state: "$state"
},
addressCount: { $sum: 1 }
}
},
{
$match: {
addressCount: { $gt: 1 }
}
},
{
$sort: {
addressCount: 1
}
},
{
$project: {
_id: 0,
name: "$_id.name",
state: "$_id.state",
address: "$addressCount"
}
}
])
Complex Queries
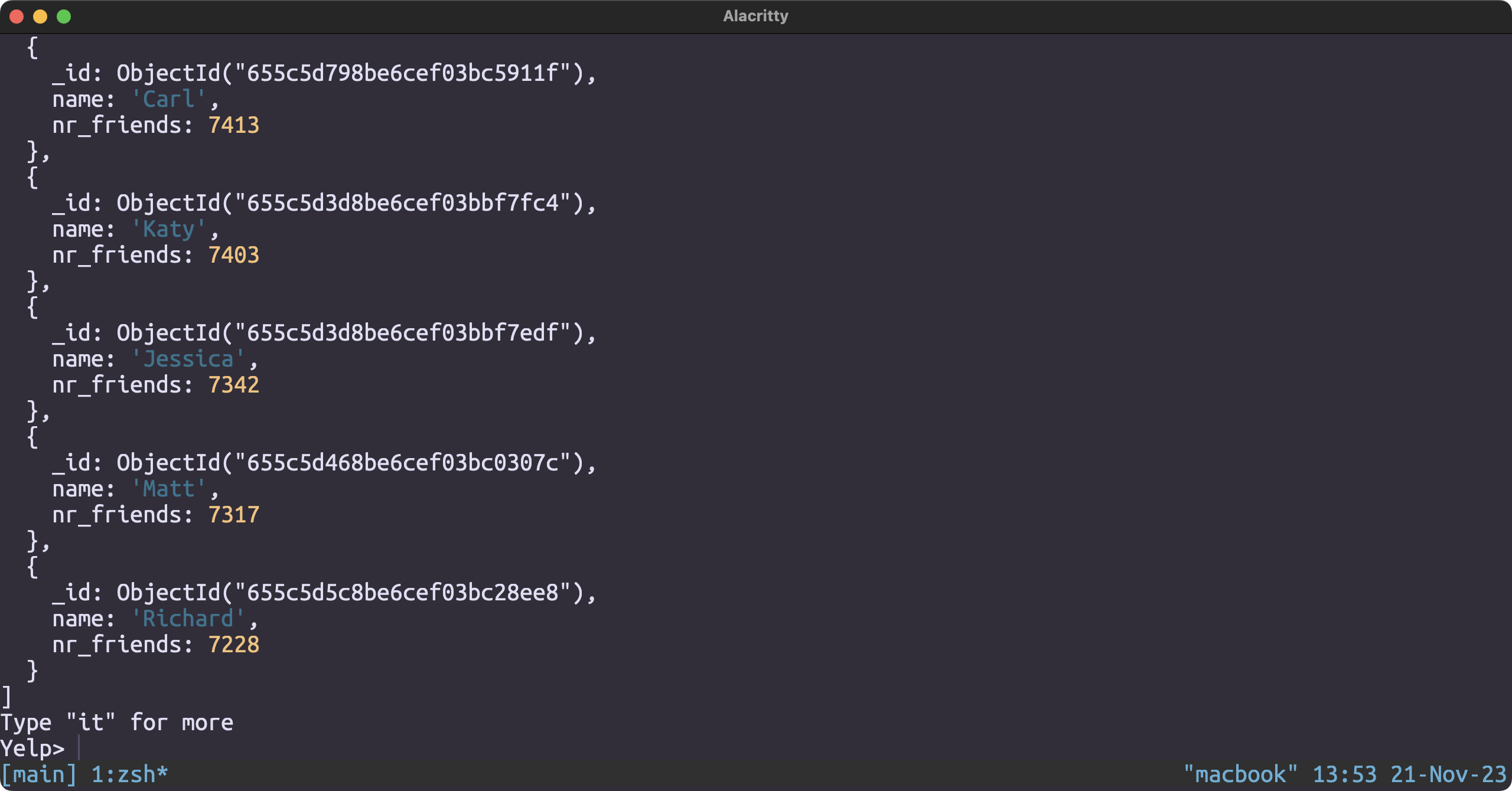
Most popular user
db.user.aggregate([
{
$project: {
name: 1,
nr_friends: {
$size: {
$ifNull: [
{ $split: ["$friends", ","] },
[]
]
}
}
}
},
{
$sort: {
nr_friends: -1
}
}
])
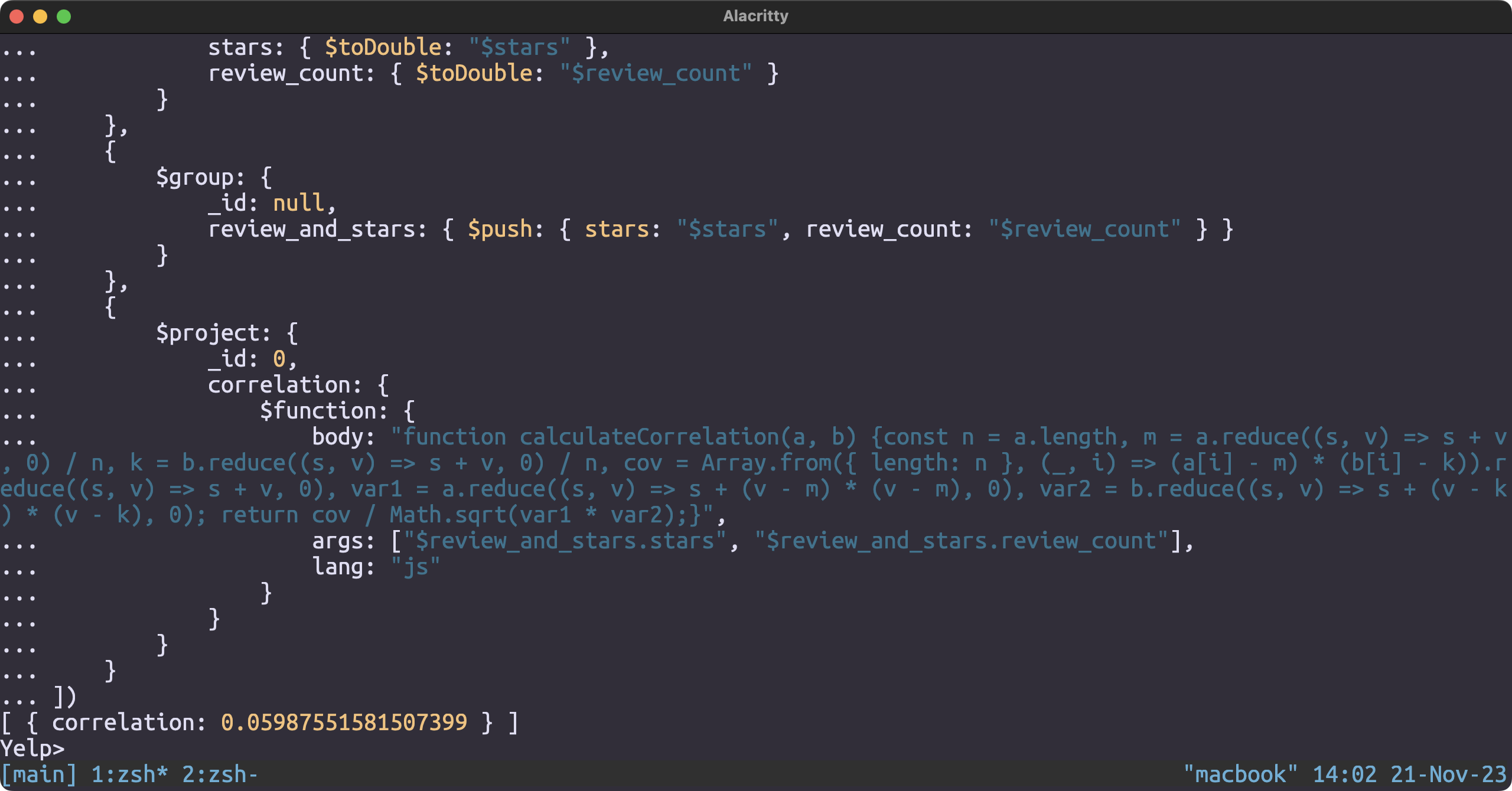
Correlation Coefficient of review_count and stars
db.business.aggregate([
{
$project: {
stars: { $toDouble: "$stars" },
review_count: { $toDouble: "$review_count" }
}
},
{
$group: {
_id: null,
review_and_stars: { $push: { stars: "$stars", review_count: "$review_count" } }
}
},
{
$project: {
_id: 0,
correlation: {
$function: {
body: "function calculateCorrelation(a, b) {const n = a.length, m = a.reduce((s, v) => s + v, 0) / n, k = b.reduce((s, v) => s + v, 0) / n, cov = Array.from({ length: n }, (_, i) => (a[i] - m) * (b[i] - k)).reduce((s, v) => s + v, 0), var1 = a.reduce((s, v) => s + (v - m) * (v - m), 0), var2 = b.reduce((s, v) => s + (v - k) * (v - k), 0); return cov / Math.sqrt(var1 * var2);}
",
args: ["$review_and_stars.stars", "$review_and_stars.review_count"],
lang: "js"
}
}
}
}
])
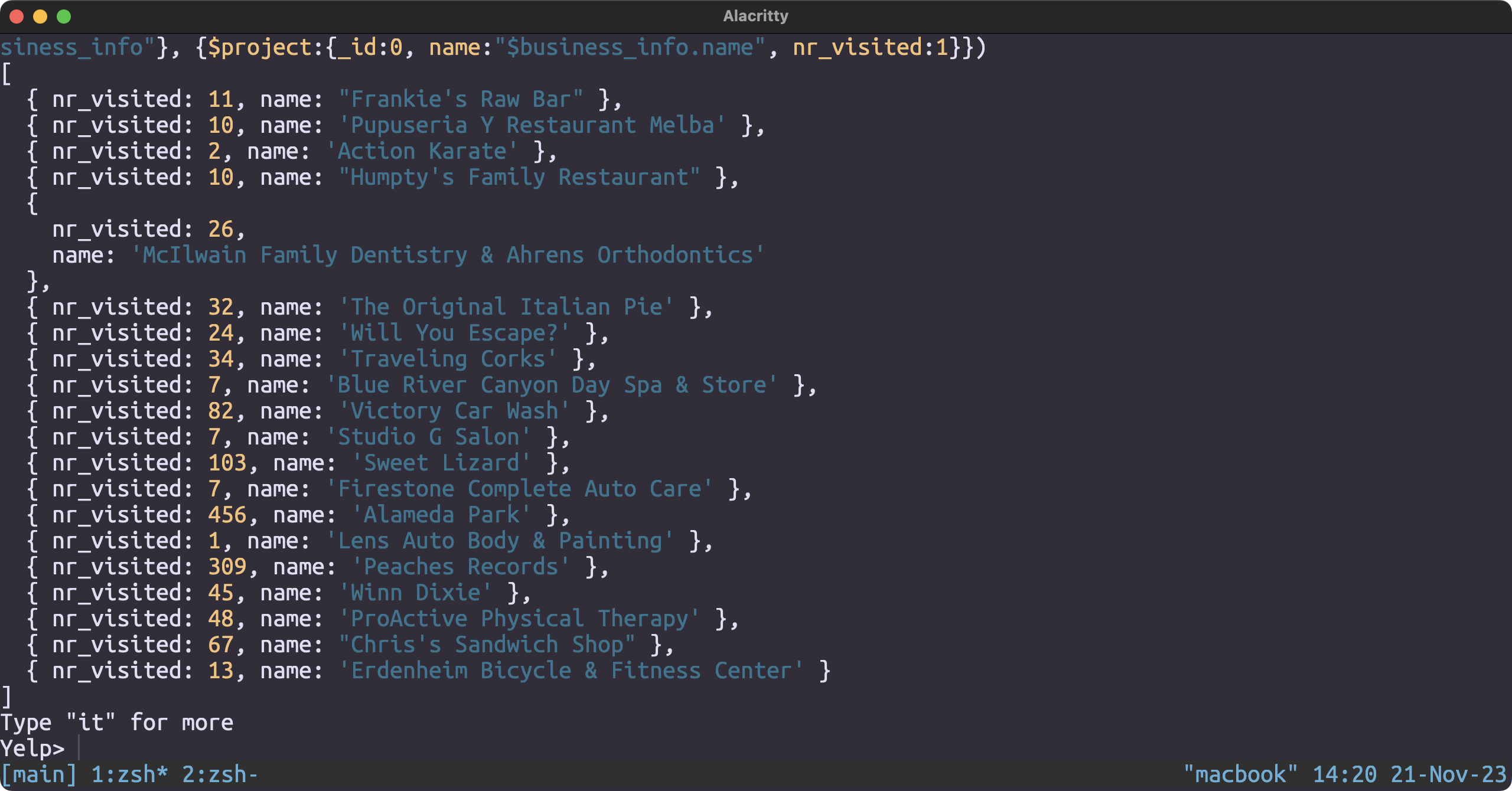
Most visited restaurant
db.checkin.aggregate([
{
$project: {
business_id: 1,
_id: 0,
nr_visited: { $size: { $split: ["$date", ","] } }
}
},
{
$lookup: {
from: "business",
localField: "business_id",
foreignField: "business_id",
as: "business_info"
}
},
{
$unwind: "$business_info"
},
{
$project: {
_id: 0,
name: "$business_info.name",
nr_visited: 1
}
}
])
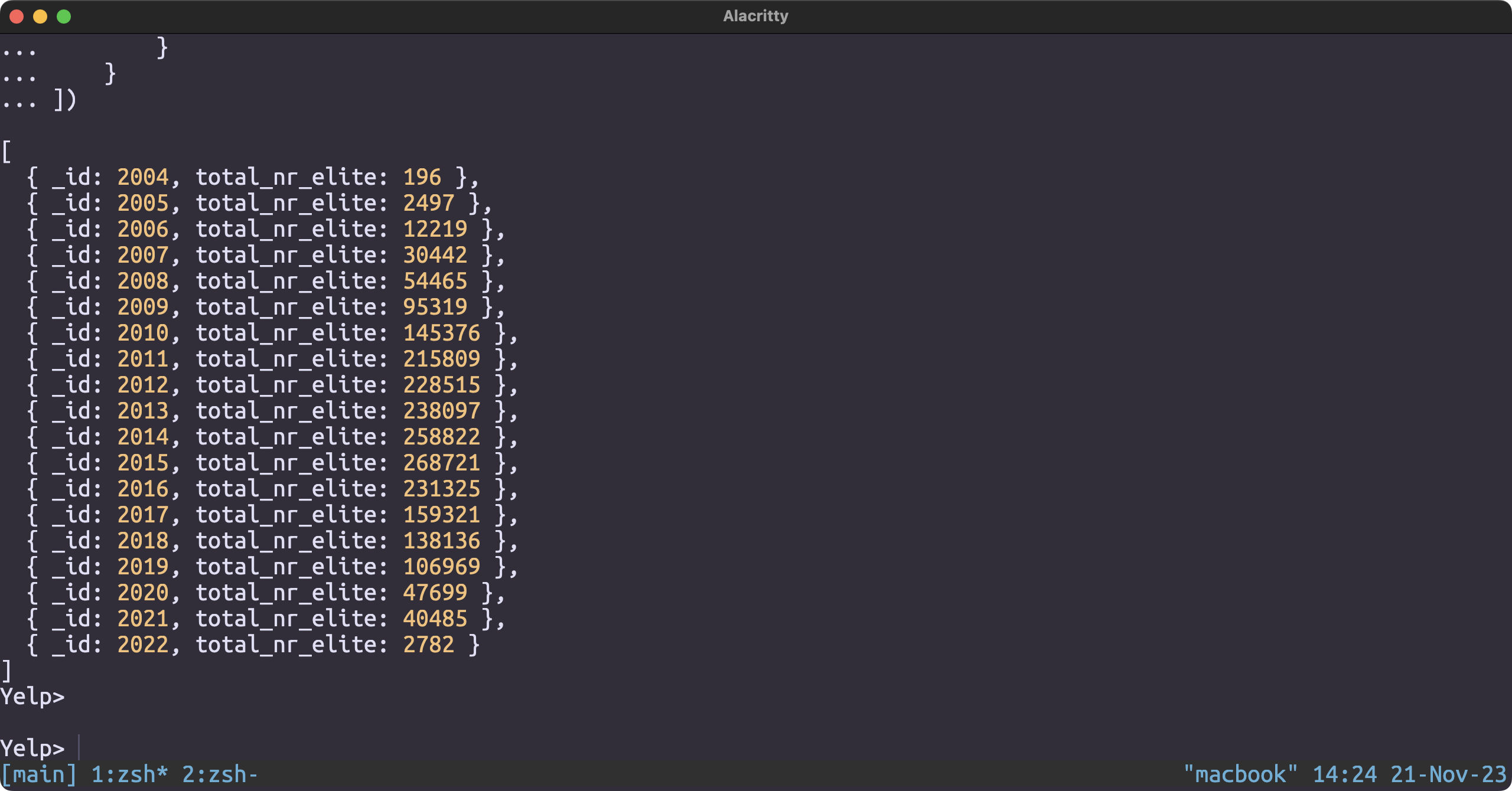
Which year produced the most number of elite users
db.user.aggregate([
{
$project: {
year: { $toInt: { $substr: ["$yelping_since", 0, 4] } },
nr_elite: { $size: { $split: ["$elite", ','] } }
}
},
{
$group: {
_id: "$year",
total_nr_elite: { $sum: "$nr_elite" }
}
},
{
$sort: {
_id: 1
}
}
])
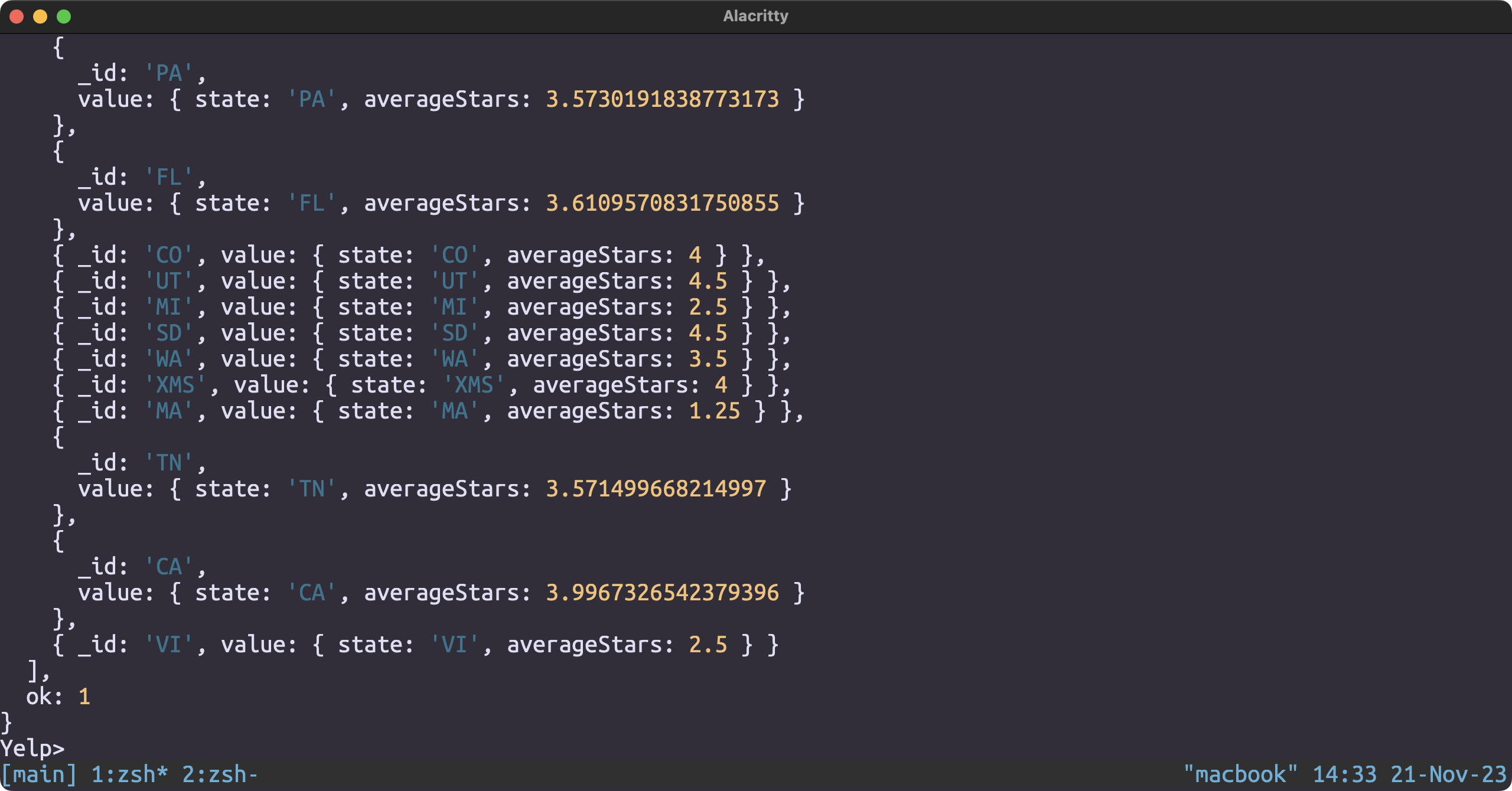
Finding Average Star by State using MapReduce
var mapFunction = function() {
emit(this.state, { totalStars: this.stars });
};
var reduceFunction = function(key, values) {
var reducedObject = { count: 0, totalStars: 0 };
values.forEach(function(value) {
reducedObject.count += 1;
reducedObject.totalStars += value.totalStars;
});
reducedObject.averageStars = reducedObject.totalStars / reducedObject.count;
return { state: key, averageStars: reducedObject.averageStars };
};
db.business.mapReduce(
mapFunction,
reduceFunction,
{
out: { inline: 1 }
}
);
Cursor
var cursor = db.business.find({"state": "AZ"})
while (cursor.hasNext()) {
var document = cursor.next();
printjson(document);
}